In a system based on messages or events, there are numerous ways that system can fail, and the techniques needed to handle those failures are different. You can’t just switch messaging infrastructure or use a framework to address all failure points. It’s also important to understand where failures can occur, even if the underlying infrastructure is perfect. Much like acknowledging that there is no happy path, the way you plan for failure affects product decisions.
Here is a common workflow showing all the moving parts:
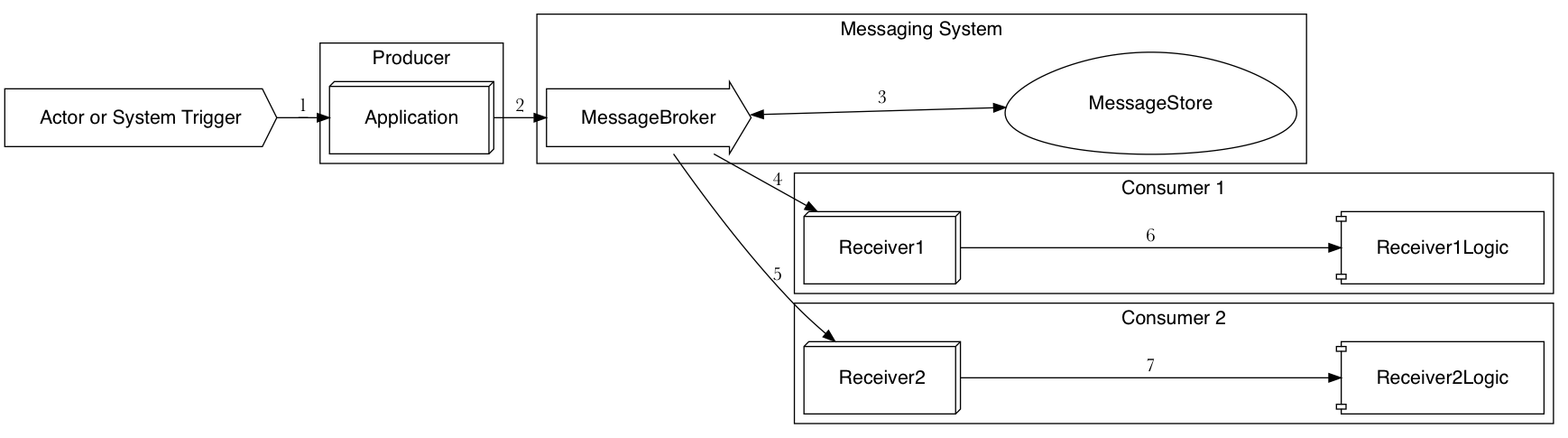
- An Actor or System Trigger initiates the workflow, triggering application logic.
- The Application executes some internal logic and sends a message.
- The Message Broker, receiving that message, stores it locally so it can send it to consumers.
- A consumer receives the message.
- Another consumer could also receive the message.
- The consumer’s reception of the message triggers some internal business logic to handle it.
- Other consumers would behave similarly.
As an example, a Merchandise Buyer might perform a markdown on some inventory. After some initial validation in the Merchandising app, this will send a message about the new price. Our warehouse software will receive this message and update its internal cache of orders to reflect the new price. A financial system might also receive this message and adjust some financial reporting that’s based on the price of this inventory.
The way we handle failure at each step is different, and the choices of technology at each part only have a limited ability to shield us from problems.
1. System Trigger
The system trigger (1) initiates everything. Common failures here are timeouts inside Application. This is particularly insidious because when this happens, the System Trigger may retry the operation. Think about a user on a webpage getting a 500 error. They will likely retry what they were doing until it succeeds.
This means that the entire workflow could be triggered multiple times, and it could be done in a way that is not programmatically obvious. Imagine our Merchandise buyer marking down an item’s price, and the entire operation succeeds but at the last minute their Internet connection dies and they get an error. They will repeat the markdown action and now there will be two messages about the inventory price being sent.
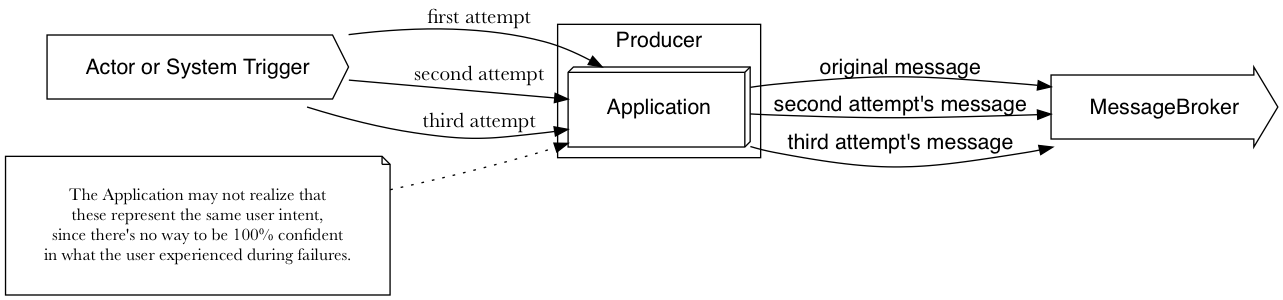
Even if your messaging system supports exactly once delivery, you will get duplicate messages. Unless you go to extreme lengths, there will likely be the possibility that the same user intent occurs multiple times, and no messaging infrastructure in the world could possibly detect that. Thus, beware anything promising exactly-once delivery. Plan for at-least once delivery always.
Once the action is triggered, some part of the application logic will send a message.
2. Business Logic That Includes Sending Messages
The Application will perform some business logic, perhaps saving information to a database. If part of that logic includes sending a message (2), what happens when the logic succeeds, but the message-sending fails?
You might try to wrap all the logic in a database transaction, so that if the message-sending fails, the underlying database changes are rolled back. This will cause your database to hold a transaction open while you make a potentially slow network connection, which can cause stress on the database.
If your business logic is even more complex, such as also making a synchronous HTTP call, guarantees become more difficult.
A practical solution would be to queue a background job to send the message in the event of a failure. That way, as long as the system you used to queue background jobs was working, you’d have confidence the message gets sent. Of course, this is hard to guarantee.
The safest means of doing this turns out to be quite complex. You must separate each step in the business logic into a self-contained job whose execution begets the next step, allowing for retries and failure along the way:

Each step is relatively easy to understand since it does so little, but you now have to orchestrate and manage these steps, and thus require some way to observe their behavior and make sure you know when a process fails in the middle.
You could achieve this entirely with your background job system. One thing to note is that because the steps are now asynchronous, the user experience has to account for this. You can no longer assume the entire operation as completed when showing the user the results.
Once we’ve sent the message, there is still the possibility of losing the message inside the messaging system.
3. Failures inside the Messaging Infrastructure
You want to be sure that when the Message Broker confirms receipt of the message that it will absolutely be sent to all interested consumers. This may not be the default configuration of your chosen messaging system.
MongoDB is famous for having a default configuration that indicated a write was successful when, in fact, that write had not been completely confirmed to disk. This meant that Mongo was telling client applications that a write was good, but then sometimes losing that write.
Messaging systems can work in a similar fashion, so be sure you’ve configured yours to provide these guarantees.
The second aspect of your messaging system is how it manages these messages while sending them to consumers.
4 & 5. Failure to Deliver or Receive a Message
The messaging system delivers the message to each consumer. What you don’t want is for the consumer to be able to lose that message if it gets interrupted processing it. Therefore, the messaging system needs to have a way for the consumer to acknowledge receipt of the message, or to ask for a message to be re-sent.
This implies that your messaging system will be managing un-acknowledged messages for all consumers. And because the messages must survive a restart of the messaging system, this means shared resources are being used for every un-acknowledged message.
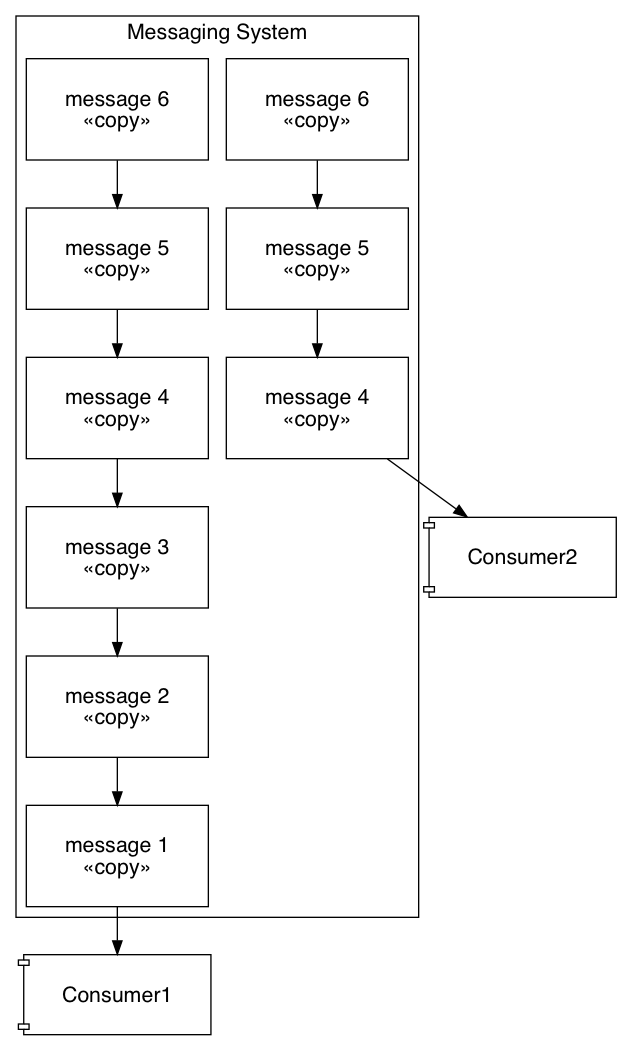
We use RabbitMQ, which stores a copy of every message in a queue for every consumer that wants that message. Meaning that if any consumer isn’t processing and acknowledging the messages, they accumulate. Here, Consumer 2 has successfully acknolwedge messages 1, 2, and 3, however Consumer 1 has not. Thus, the messaging system must hold onto copies of messages 1, 2, and 3 until Consumer 1 acknowledges that it’s processed them:
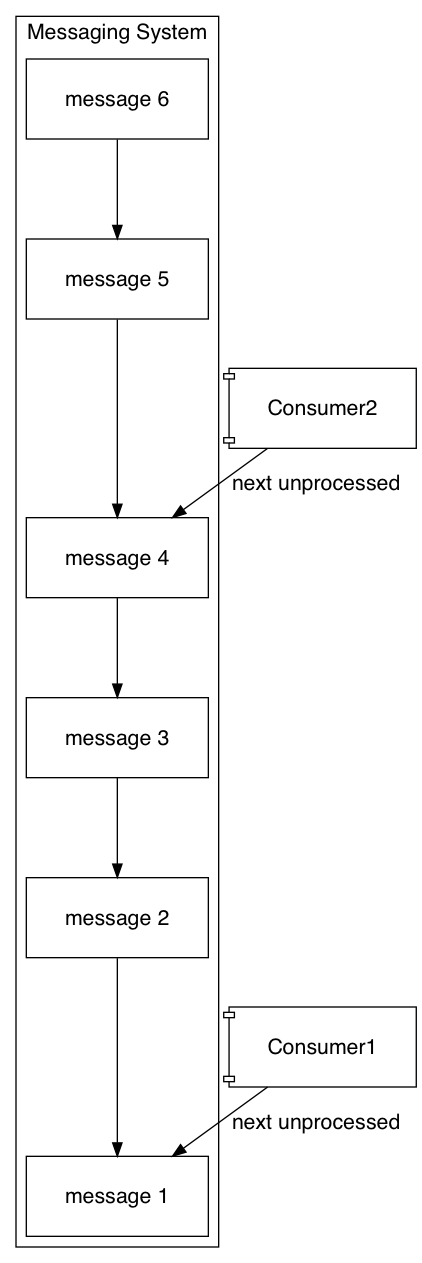
Apache Kafka, on the other hand, stores the messages as a log, making it possible for consumers to remember where they’ve left off processing. You configure the system to store a particular number of messages historically, say a week’s worth. As long as all consumers process all messages within a week, nothing is lost. Here there is a stable set of messages, and each consumer remembers how “far long” in the log it’s processed messages. The consumers keep track of this:
In any case, you have to know how things will behave. This also affects how you design the consumer’s business logic, because presumably the consumer needs to process the messages in some way.
6 & 7. Consumer Business Logic
Ideally, the consumer only signals that it’s processed a message once all downstream logic has executed. This logic, however, could be time-consuming and fall victim to any number of failure modes. Because your messaging system is a shared resource, this means you run the risk of affecting other systems.
We’ve experienced this failure mode several times. A message handler experiences a failure in business logic, and the messages aren’t acknowledged. The messages back up, eventually consuming all resources on the RabbitMQ server, causing it to fall over. And because we rely so heavily on it, this takes down many of our applications!
To combat this, you want to divorce acknowledging the message from processing it. This is the reverse of what we saw earlier, where you could store the received message somewhere safe (like a database), and then process it internally to your application.

We tend to do this by configuring a common message handler that simply queues a background job with the message payload. As long as our background job system is working, we won’t create a backup in Rabbit.
Managing a System Like This
There’s a couple things to take away. First, there is a meta-lesson about understanding the behavior of each part of your system, and tailoring your failure response, software design, and user experience to handle it. Second, it’s that achieving fault-tolerance in a distributed, message-based system requires lots of small tasks that can be pieced together. A coarse-grained monolithic system would have difficulty managing the failures that could happen, because it would be implemented assuming a lot of things won’t go wrong that actually can.
Thinking about the specific failure modes is a fairly motivating example for having an event-sourced, reactive system architecture. The problem is that creating a system like this from scratch could be ill-advised. If your original goal is to provide a basic user experience and save some data to a database, a highly-complex message-based system would be overkill. But, if that system grows, you need a path forward. That’s a discussion for another day :)