Standard natural language processing (NLP) is a messy and difficult affair. It requires teaching a computer about English-specific word ambiguities as well as the hierarchical, sparse nature of words in sentences. At Stitch Fix, word vectors help computers learn from the raw text in customer notes. Our systems, composed of machines and human experts, need to recommend the maternity line when she says she’s in her ‘third trimester’, identify a medical professional when she writes that she ‘used to wear scrubs to work’, and distill ‘taking a trip’ into a Fix for vacation clothing.
While we’re not totally “there” yet with the holy grail to NLP, word vectors (also referred to as distributed representations) are an amazing tool that sweeps away some of the issues of dealing with human language. The machines work in tandem with the stylists as a support mechanism to help identify and summarize textual information from the customers. The human experts will make the final call on what actions will be taken. The goal of this post is to be a motivating introduction to word vectors and demonstrate their real-world utility.
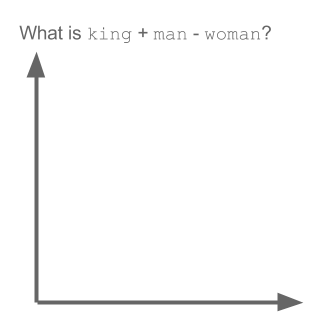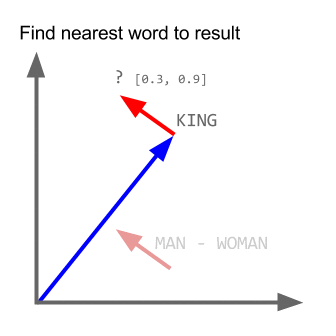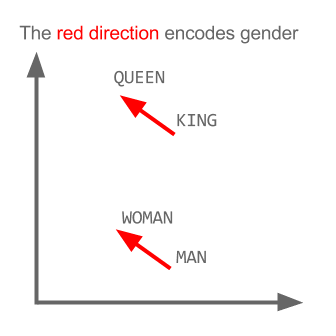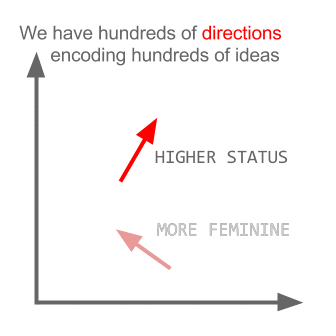
The following example set the natural language community afire1 back in 2013:
\[king - man + women = queen\]In this example, a human posed a question to a computer: what is king - man + woman? This is similar to an SAT-style analogy (man is to woman as king is to what?). And a computer solved this equation and answered: queen. Under the hood, the machine gets that the biggest difference between the words for man and woman is gender. Add that gender difference to king, and you get queen.
This is astonishing because we’ve never explicitly taught the machine anything about gender!
In fact, we’ve never handed the computer anything like a dictionary, a thesaurus, or a network of word relationships. We haven’t even tried to break apart a sentence into its constituent parts of speech2. We’ve simply fed a mountain of text into an algorithm called word2vec and expected it to learn from context. Word by word, it tries to predict the other surrounding words in a sentence. Or rather, it internally represents words as vectors, and given a word vector, it tries to predict the other word vectors in the nearby text3.
The algorithm eventually sees so many examples that it can infer the gender of a single word, that both the The Times and The Sun are newspapers, that The Matrix is a sci-fi movie, and that the style of an article of clothing might be boho or edgy. That word vectors represent much of the information available in a dictionary definition is a convenient and almost miraculous side effect of trying to predict the context of a word.
Internally high dimensional vectors stand in for the words, and some of those dimensions are encoding gender properties. Each axis of a vector encodes a property, and the magnitude along that axis represents the relevance of that property to the word4. If the gender axis is more positive, then it’s more feminine; more negative, more masculine.
Applied appropriately,word vectors are dramatically more meaningful and more flexible than current techniques5 and let computers peer into text in a fundamentally new way. It’s surprisingly easy to get started using libraries like gensim (in Python) or Spark (in Scala & Python) – all you need to know is how to add, subtract, and multiply vectors!
Let’s review the new abilities that word vectors grant us.
Similar words are nearby vectors
Similar words are nearby vectors in a vector space. This is a powerful convention since it lets us wipe away a lot of the noise and nuance in vocabulary. For example, let’s use gensim to find a list of words similar to vacation using the freebase skipgram data6:
from gensim.models import Word2Vec
fn = "freebase-vectors-skipgram1000-en.bin.gz"
model = Word2Vec.load_word2vec_format(fn)
model.most_similar('vacation')
# [('trip', 0.7234684228897095),
# ('honeymoon', 0.6447688341140747),
# ('beach', 0.6249285936355591),
# ('vacations', 0.5868890285491943),
# ('wedding', 0.5541957020759583),
# ('resort', 0.5231006145477295),
# ('traveling', 0.5194448232650757),
# ('vacation.', 0.5068142414093018),
# ('vacationing', 0.5013546943664551)]
We’ve calculated the vectors most similar to the vector for vacation, and then looked up what words those vectors represent. As we read the list, we note that these words aren’t just similar in vector space, but that they make sense intuitively too.
In this case, we’ve looked for vectors that are nearby to the word vacation by measuring the similarity (usually cosine similarity) to the root word and sorting by that.
Destinations
Vacation
Season
Holidays
Wedding
Month
Above is an interactive visualization of the words nearest to vacation. The more similar a word to it’s genre, the larger the radius of the marker. Hover over the bubbles to reveal the words they represent7.
And these words aren’t just nearby; they’re also in several clusters. So we can determine that the words most similar to vacation come in a variety of flavors: one cluster might be wedding-related, but another might relate to destinations like Belize.
Of course our human stylists understand when a client says “I’m going to Belize in March” that she has an upcoming vacation. But the computer can potentially tag this as a ‘vacation’ fix because the word vector for Belize is similar to that for vacation. We can then make sure that the Fixes our customers get are vacation-appropriate!
Ideas are words that can be added & subtracted
We have the ability to search semantically by adding and subtracting word vectors8. This empowers us to creatively add and subtract concepts and ideas. Let’s start with a style we know a customer liked, item_3469:

Our customer recently became pregnant, so let’s try and find something like item_3469 but along the pregnant dimension:
model.most_similar('ITEM_3469', 'pregnant')
matches = list(filter(lambda x: 'ITEM_' in x[0], matches))
# ['ITEM_13792',
# 'ITEM_11275',
# 'ITEM_11868']
Of course the item IDs aren’t immediately informative, but the pictures let us know that we’ve done well:

The first two are items have prominent black & white stripes like item_3469 but have the added property that they’re great maternity-wear. The last item changes the pattern away from stripes but is still a loose blouse that’s great for an expectant mother. Here we’ve simply added the word vector for pregnant to the word vector for item_3469, and looked up the word vectors most similar to that result9.
Our stylists tailor each Fix to their clients, and this prototype system may free them to mix and match artistic concepts about style, size and fit to creatively search for new items.
Summarizing sentences & documents
At Stitch Fix, we work hard to craft a uniquely-styled Fix for each of our customers. At every stage of a Fix we collect feedback: what would you like in your next Fix? What did you think of the items we sent you? What worked? What didn’t?
The spectrum of responses is myriad, but vectorizing those sentences10 allows us to begin systematically categorizing those documents:
from gensim.models import Doc2Vec
fn = "word_vectors_blog_post_v01_notes"
model = Doc2Vec.load(fn)
model.most_similar('pregnant')
matches = list(filter(lambda x: 'SENT_' in x[0], matches))
# ['...I am currently 23 weeks pregnant...',
# '...I'm now 10 weeks pregnant...',
# '...not showing too much yet...',
# '...15 weeks now. Baby bump...',
# '...6 weeks post partum!...',
# '...12 weeks postpartum and am nursing...',
# '...I have my baby shower that...',
# '...am still breastfeeding...',
# '...I would love an outfit for a baby shower...']
In this example we calculate which sentences are closest to the word pregnant. This list also skips over many literal matches of pregnant in order to demonstrate the more advanced capabilities. We’ve also censored sentences to keep out personally identifying text. Also note that the last sentence is a false positive: while similar to the word pregnant, she’s unlikely to be interested in maternity clothing.
This allows us to understand not just what words mean, but condense our client comments, notes, and requests in a quantifiable way. We can for example categorize our sentences by first calculating the similarity between a sentence and a word:
def get_vector(word):
return model.syn0norm[model.vocab[word].index]
def calculate_similarity(sentence, word):
vec_a = get_vector(sentence)
vec_b = get_vector(word)
sim = np.dot(vec_a, vec_b)
return sim
calculate_similarity('SENT_47973, 'casual')
# 0.308
We calculated the overlap between a sentence with label SENT_47973 and the word casual. The sentence is previously trained from this customer text: ‘I need some weekend wear. Comfy but stylish.’ The similarity to casual is about 0.308, which is pretty high.
Having built a function that computes the similarity between a sentence and a word, we can build a table of customer comments and their similarities to a given topic:
| raw text snippets | ‘broken’ | ‘casual’ | ‘pregnant’ |
|---|---|---|---|
| ‘… unfortunately the lining ripped after wearing if twice …’ | 0.281 | 0.082 | 0.062 |
| ‘… I need some weekend wear. Comfy but stylish.’ | 0.096 | 0.308 | 0.191 |
| ‘… 12 weeks postpartum and am nursing …’ | 0.158 | 0.110 | 0.378 |
A table like this around helps us quickly answer how many people are looking for comfortable clothes or finding defects in the clothing we send them.
What we didn’t mention
While word vectorization is an elegant way to solve many practical text processing problems, it does have a few shortcomings and considerations:
-
Word vectorization requires a lot of text. You can download pretrained word vectors yourself, but if you have a highly specialized vocabulary then you’ll need to train your own word vectors and have a lot of example text. Typically this means hundreds of millions of words, which is the equivalent of 1,000 books, 500,000 comments, or 4,000,000 tweets.
-
Cleaning the text. You’ll need to clean the words of punctuation and normalize Unicode11 characters, which can take significant manual effort. In this case, there are a few tools that can help like FTFY, SpaCy, NLTK, and the Stanford Core NLP. SpaCy even comes with word vector support built-in.
-
Memory & performance. The training of vectors requires a high-memory and high-performance multicore machine. Training can take several hours to several days but shouldn’t need frequent retraining. If you use pretrained vectors, then this isn’t an issue.
-
Databases. Modern SQL systems aren’t well-suited to performing the vector addition, subtraction and multiplication searching in vector space requires. There are a few libraries that will help you quickly find the most similar items12: annoy, ball trees, locality-sensitive hashing (LSH) or FLANN.
-
False-positives & exactness. Despite the impressive results that come with word vectorization, no NLP technique is perfect. Take care that your system is robust to results that a computer deems relevant but an expert human wouldn’t.
Conclusion
The goal of this post was to convince you that word vectors give us a simple and flexible platform for understanding text. We’ve covered a few diverse examples that should help build your confidence in developing and deploying NLP systems and what problems they can solve. While most coverage of word vectors has been from a scientific angle, or demonstrating toy examples, we at Stitch Fix think this technology is ripe for industrial application.
In fact, Stitch Fix is the perfect testbed for these kinds of new technologies: with expert stylists in the loop, we can move rapidly on new and prototypical algorithms without worrying too much about edge and corner cases. The creative world of fashion is one of the few domains left that computers don’t understand. If you’re interested in helping us break down that wall, apply!
Further reading
There are a few miscellaneous topics that we didn’t have room to cover or were too peripheral:
-
There’s an excellent nuts and bolts explanation and derivation of the word2vec algorithm. There’s a similarly useful iPython Notebook version too.
-
Translating word-by-word English into Spanish is equivalent to matrix rotations. This means that all of the basic linear algebra operators (addition, subtraction, dot products, and matrix rotations) have meaningful functions on human language.
-
Word vectors can also be used to find the odd word out.
-
Interestingly, the same skip-gram algorithm can be applied to a social graph instead of sentence structure. The authors equate a sequence of social network graph visits (a random walk) to a sequence of words (a sentence in word2vec) to generate a dense summary vector.
-
A brief but very visual overview of distributed representations is available here.
-
Intriguingly, the word2vec algorithm can be reinterpreted as a matrix factorization method using point-wise mutual information. This theoretical breakthrough cleanly connects older and faster but more memory-intensive techniques with word2vec’s streaming algorithm approach.
1 See also the original papers, and the subsequently bombastic media frenzy, the race to understand why word2vec works so well, some academic drama on GloVe vs word2vec, and a nice introduction to the algorithms behind word2vec from my friend Radim Řehůřek. ←
2 Although see Omer Levy and Yoav Goldberg’s post for an interesting approach that has the word2vec context defined by parsing the sentence structure. Doing this introduces a more functional similarity between words (see this demo). For example, Hogwarts in word2vec is similar to dementors and dumbledore, as they’re all from Harry Potter, while parsing context gives sunnydale and colinwood as they’re similarly prestigious schools. ←
3 This is describing the ‘skip-gram’ mode of word2vec where the target word is asked to predict the surrounding context. Interestingly, we can also get similar results by doing the reverse: using the surrounding text to predict a word in the middle! This model, called continuous bag-of-words (CBOW), loses word order and so we lose a bit of grammatical information since that’s very sensitive to the position of a word in a sentence. This means CBOW-trained word vectors tend to do worse in a syntactic sense: the resulting vectors more poorly encode whether a word is an adjective or a verb, or a noun. ←
4 More generally, a linear combination of axes encodes the properties. We can attempt to rotate into the correct basis by using PCA (as long as we only include a few nearby words) or visualize that space using t-SNE (although we lose the concept of a single axis encoding structure). ←
5 Compare word vectors to sentiment analysis, which effectively distills everything into one dimension of ‘happy or sad’, or document labeling efforts like Latent Dirichlet Allocations that sort words into a few types. In either case, we can only ask these simpler models to categorize new documents into a few predetermined groups. With word vectors we can encapsulate far more diversity without having to build a labeled training text (and thus with less effort.) ←
6 You can download this file freely from here. ←
7
This is using an advanced visualization technique called t-SNE. This allows us to project down to 2D while still trying to maintain the local structure. This helps pop up the several word clusters that are near to the word vacation.
←
8 Check out this live demo with just wikipedia words here. ←
9 We’ve used cosine similarity to find the nearest items, but, we could’ve chosen the 3COSMUL method. This combines vectors multiplicatively instead of additively and seems to get better results (pdf warning!). This stays truer to cosine distance and in general prevents one word from dominating in any one dimension. ←
10 You can easily make a vector for a whole sentence by following the Doc2Vec tutorial (also called paragraph vector) in gensim, or by clustering words using the Chinese Restaurant Process. ←
11 If you’re using Python 2, this is a great reason to reduce Unicode headaches and switch to Python 3. ←
12 See a comparison of these techniques here. My recommendation is using LSH if you need a pure Python solution, and annoy if you need a solution that is memory light. ←