It’s natural to want to sit next to the people we work with most. Doing so makes pair-coding easier, facilitates conversations that need to happen anyway, and — in general — promotes a certain efficiency.
There’s an alternative point of view, though: if people who don’t often work closely together sit together, conversations will occur that otherwise would not.
With 79 people on our Data Science team, divided into 4 main teams, it would be easy for people to want to cluster into much smaller working groups, and be somewhat isolated from the larger team. We don’t worry about impairing intra-team communication by not having them sit together; teams have a natural gravitational pull that keeps them close (team meetings, shared priorites, etc). In order to combat this tendency, to discover new angles on research projects, find new lunch buddies, and generally feel like a more cohesive 79-person unit, we shuffle our seats every 3-6 months. We ensure that the 4 team directors sit together, to encourage high-level inter-team communication. Aside from that, a random-number generator determines our seating.
The jupyter notebook linked here has performed our last 3 shuffles. If it works for your purposes, please feel free to use it!
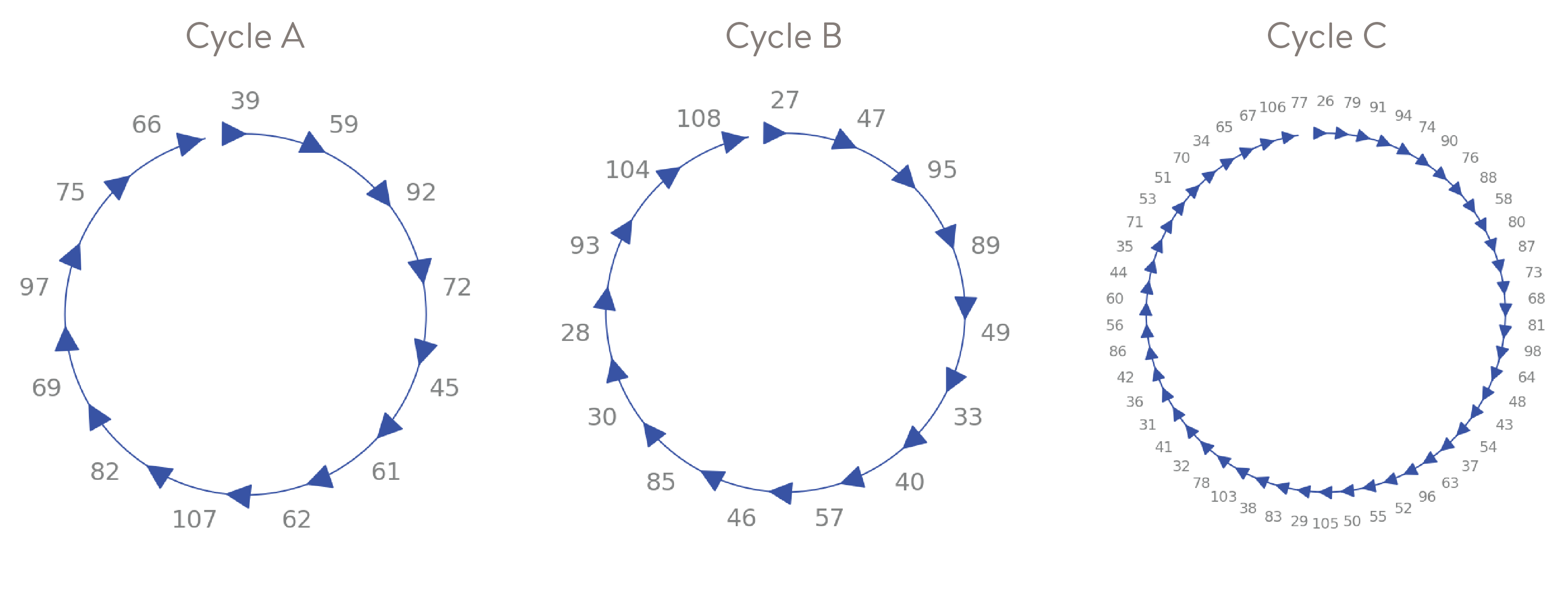
The code produces a visualization of the shuffled seating (the “Updated Seating Plan” image below), which is specific to our seat layout, but can be tweaked to work for yours. Also, to minimize collisions while changing seats (and mostly just for fun), it factors the reseating permutation into a product of disjoint cycles and visualizes the cycles. In the cycles shown below, for instance, Cycle A shows that the person in seat 39 moves to seat 59; the person in seat 59 moves to seat 92, … and the person in seat 66 moves to seat 39. And so on.