Introduction
As a frontend engineer on the Algorithms & Analytics team at Stitch Fix, I work with data scientists to develop applications and visualizations to help our internal business partners make data-driven decisions. I envisioned a platform that would assist data scientists in the data exploration process, allowing them to visually explore and rapidly iterate through their assumptions, then share their insights with others. This would align with our team’s philosophy of having engineers “deploy platforms, services, abstractions, and frameworks that allow the data scientists to conceive of, develop, and deploy their ideas with autonomy”, and solve the pain of data exploration.
The final product, code-named Dora, is built with React, Redux and Victory, backed by Elasticsearch to enable fast and iterative data exploration, and uses Spark to move data from our S3 data warehouse into the Elasticsearch cluster.
Why not just use Kibana?
The first question I got from our data platform engineers was, “Why not just use Kibana?”. Elasticsearch’s built-in visualization tool, Kibana, is robust and the appropriate tool in many cases. However, it is geared specifically towards log exploration and time-series data, and we felt that its steep learning curve would impede adoption rate among data scientists accustomed to writing SQL. The solution was to create something that would replicate some of Kibana’s essential functionality while hiding Elasticsearch’s complexity behind SQL-esque labels and terminology (“table” instead of “index”, “group by” instead of “sub-aggregation”) in the UI.
Elasticsearch’s API is really well-suited for aggregating time-series data, indexing arbitrary data without defining a schema, and creating dashboards. For the purpose of a data exploration backend, Elasticsearch fits the bill really well. Users can send an HTTP request with aggregations and sub-aggregations to an index with millions of documents and get a response within seconds, thus allowing them to rapidly iterate through their data.
Moving Data From S3 to Elasticsearch with Spark
To load data from our S3 data warehouse into the Elasticsearch cluster, I developed a Spark application that uses PySpark to extract data from S3, partition, then batch-send each partition to Elasticsearch to increase parallelism. The Spark job enables fielddata: true for text columns with low cardinality to allow sub-aggregations by text columns and prevents data duplication by adding a unique _id field to each row in the dataframe.
# Use SparkSQL to extract data from a table in S3.
df = spark_context.sql("select * from {}.{}".format(schema, table))
# Partition the dataframe and batch send each partition.
df.repartition(num_of_partitions).foreachPartition(send_batch)
The job can then be run by data scientists in Flotilla, an internal data platform tool for running jobs on Amazon’s ECS, with environment variables specifying which schema and table to load.
React & Redux
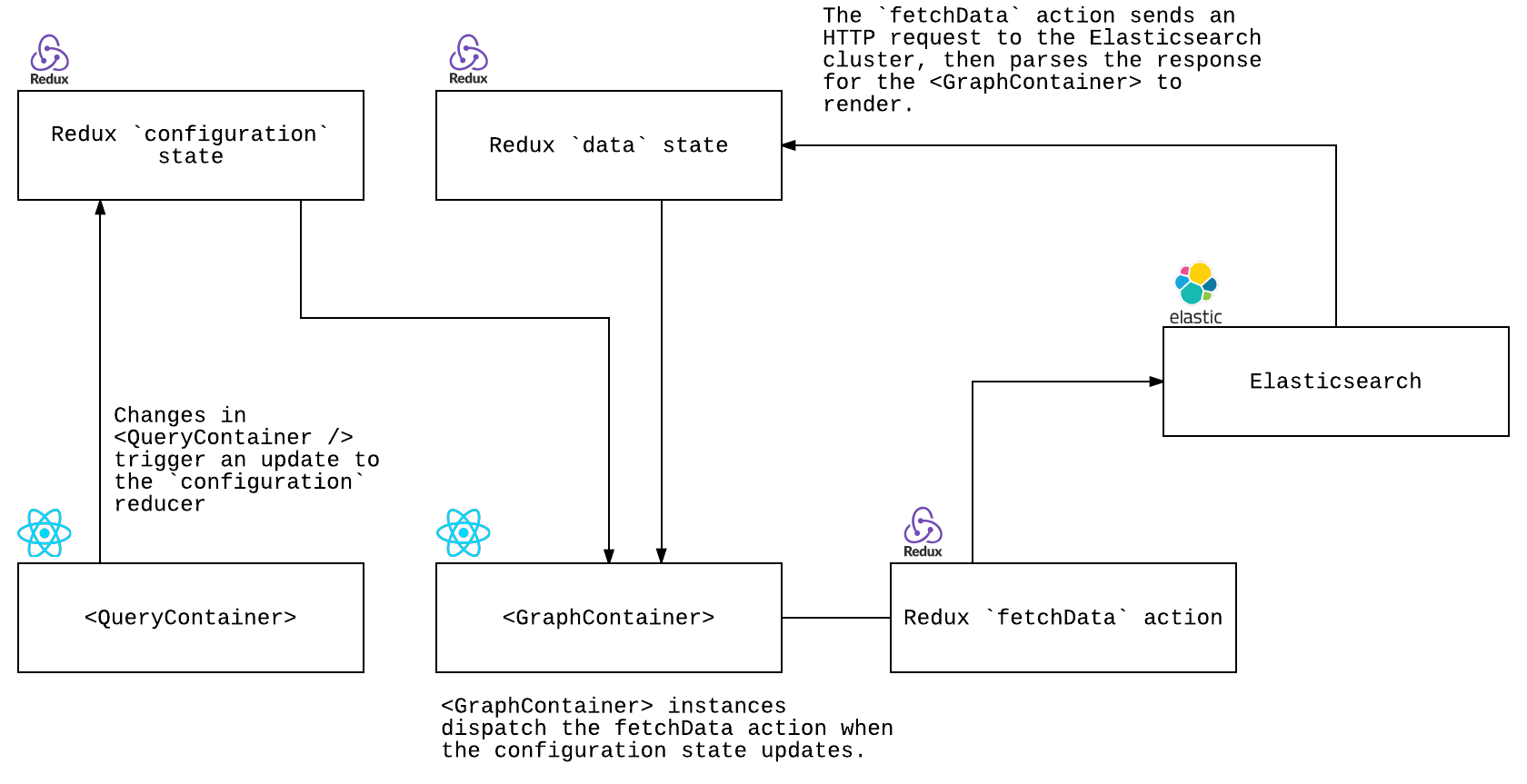
In the UI, Redux is used for client-side state management. The two most important pieces of state are configuration and data. The configuration state stores the configuration for each graph, each keyed by an UUID and consisting of graph property key/value pairs. When certain properties update, an Elasticsearch query is built from the configuration and sent to the Elasticsearch index’s /_search endpoint. The ensuing response is then parsed and stored in the data state.
// Redux Store
{
configuration: {
[graphUUID]: {
graphTitle: 'My Graph',
esIndex: 'my_schema.my_table',
aggregations: [
{ type: avg, column: 'some_column' }
],
// Other graph properties.
}
},
data: {
[graphUUID]: [
{
aggregationMetric: {...},
groupBy: {...},
data: [{x: 0, y: 100}, ...]
}
]
},
// Elasticsearch indices metadata.
indices,
// Global UI state.
globals
}
Diving deeper into the various graph properties that make up the configuration, we can classify each property as shallow (a singular value, such as which Elasticsearch index to query) or nested (an array of values, such as the list of aggregations to plot). Additionally, certain properties affect the query being sent to Elasticsearch while others only affect the presentation. These graph properties are represented graphically as child components of the <QueryContainer> parent component. To provide a consistent interface for the variety of graph property components to interact with the Redux store, they are decorated with the queryConnect higher-order component, which exposes an onChange prop for shallow properties and an onAdd, onEdit, and onDelete prop for nested properties.
// queryConnect.js
export default function queryConnect(type, mapStateToProps) {
return (UnwrappedComponent) => {
const WrappedComponent = class extends Component {
handleChange({ uuid, properties }) {
this.props.dispatch(editShallowGraphProperties({
uuid,
properties
}))
}
render() {
return (
<UnwrappedComponent onChange={this.handleChange} />
)
}
}
// Component is connected to the Redux store here.
return connect(mapStateToProps)(WrappedComponent)
}
}
// SomeQueryComponent.js
class SomeQueryComponent extends Component {
onChange(value) {
const { uuid, onChange } = this.props
this.props.onChange({
uuid: this.props.uuid,
properties: {
xAxisMetric: value
}
})
}
// Other methods.
}
export default queryConnect('shallow', mapStateToProps)(SomeQueryComponent)
Once a query-modifying graph property has been updated, the <GraphContainer> component will dispatch the fetchData action, sending an HTTP request to Elasticsearch and rendering the response into Victory’s visualization components. While we have historically used React and D3 for data visualization, we opted to use Victory for several reasons. It does a great job of integrating React and D3 (something notoriously tedious to do), provides a developer-friendly API in the form of React components, and is highly extensible. Thus, synchronizing React and D3 is delegated to Victory and we can focus on building custom React SVG components on top of it.
// Custom SVGs to complement Victory base components.
import CustomHover from './CustomHover'
import CustomAnnotation from './CustomAnnotation'
class VisualizationContainer extends Component {
// Other methods.
renderVisualizations(datum, index) {
const sharedProps = {...}
switch(this.props.graphType) {
case 'BAR':
return React.cloneElement(
this.renderVictoryLine(args),
sharedProps
)
// Handle other graph types.
}
}
render() {
return (
<VictoryChart
// Use the VictoryVoronoiContainer component to handle
// mousemove events.
containerComponent={
<VictoryVoronoiContainer
dimension="x"
labelComponent={<CustomHover />}
/>
}
>
{/*
Render other components, such as axes and annotations.
*/}
{this.props.data.map((d, i) => this.renderVisualizations(d, i))}
</VictoryChart>
)
}
}
Summary
Dora helps data scientists at Stitch Fix visually explore their data - such as forecasting client demand, looking at the distribution of clients in a particular segment, and viewing inventory levels. Powered by React and Elasticsearch, it provides an intuitive UI for data scientists to take advantage of Elasticsearch’s powerful functionality. Additionally, it aligns with our team’s goal of building horizontal platforms to enable data science. Moving forward, I’m excited to continue building out this platform and other data visualization tools at Stitch Fix!