Stitch Fix is a Data Science company that aspires to help you to find the style that you love. Data Science helps us make most of our business and strategic decisions.
At Stitch Fix, our Data Scientists run 1000s of Spark jobs every day. This post describes the tooling we’ve put in place to abstract the complexity of developing and scheduling these jobs in production and executing them on an elastic number of clusters.
Infrastructure
Stitch Fix’s data infrastructure is housed completely on Amazon AWS. A huge advantage to running in that environment is that storage can easily be decoupled from compute. That decoupled storage layer is S3.
This allows us to be flexible and gives us the ability to run multiple clusters against the same data layer. We have also built tooling that allows our Data Scientists to create and terminate ad-hoc clusters without much hassle.
The transient nature of the clusters should not be an issue or concern for Data Scientists. They should not worry about the execution environment and how to interact with it. Genie and the tools around it, help us in making that possible.
Let’s have a closer look at Genie.
Genie
Genie has been an integral part of Stitch Fix’s Compute infrastructure. It was created and open sourced by Netflix (Genie) and this is where it fits within our Spark architecture.
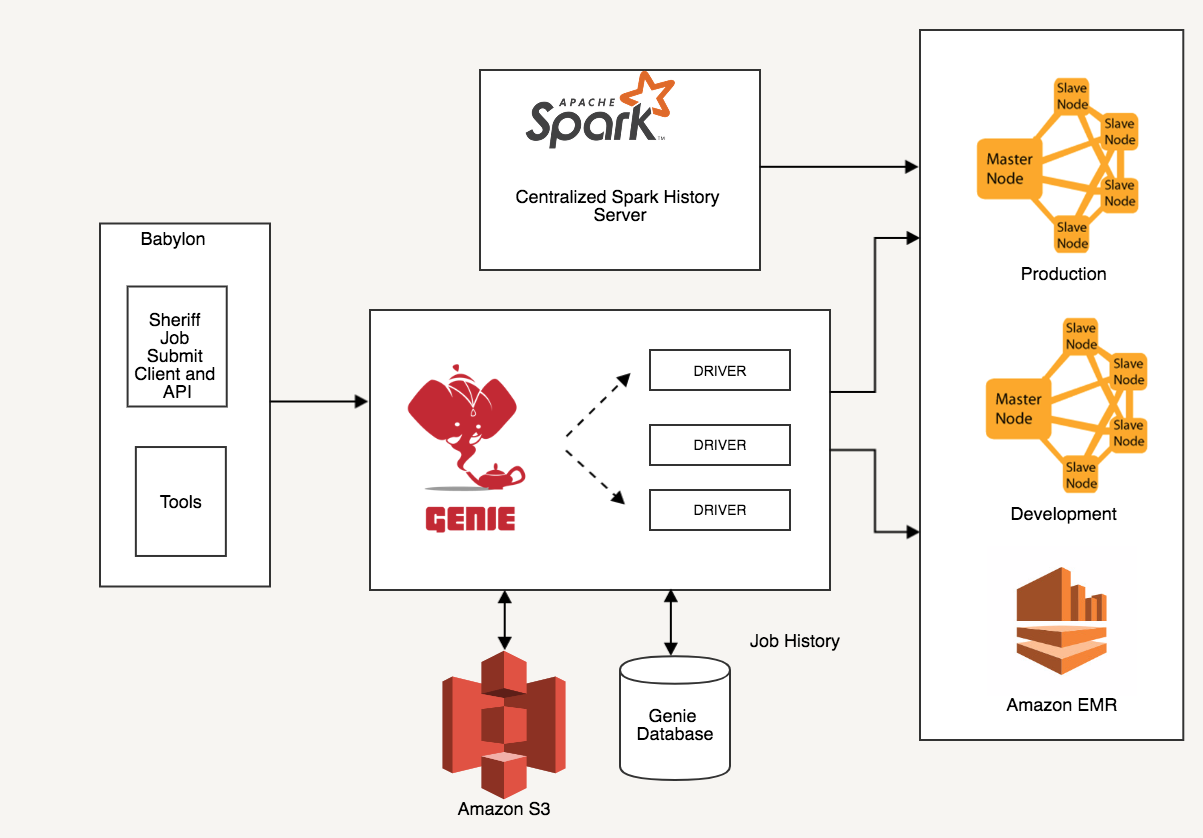
Genie helps us accomplish the following unique functions.
Spark Indirection
At Stitch Fix, we run our own custom builds of Apache Spark. This means we can bump minor versions, add patches, and add custom scripts to our heart’s content.
Today our Spark 2.x version may reference a custom build of Spark 2.1.0, tomorrow it might reference a custom build of Spark 2.2.0.
At the end of the day, Data scientists don’t want to worry if they’re running our build of Spark 2.1.0 or Spark 2.2.0.
Red/Black Cluster Deployment
If we ever need to redeploy our clusters, we can do so without disrupting the workflow and without any coordination with our Data Science teams. Genie’s data model specifically supports it.
Here is an overview of the additional tooling we built for Spark.
Babylon
Babylon is our internal tool that helps a Spark job start and head to Genie.
Sheriff of Babylon
Sheriff is our command line tool and Genie client library that we built to abstract Data Scientists’ interactions with Genie. Sheriff handles job submissions. Thus, Data Scientists don’t have to be concerned about Genie’s API calls. The same command line is used to both iterate on jobs during development and schedule them in production.
Overrides
Default settings have been useful for Data Scientists. These include executor memory (4G), executor cores (3) and driver_memory (4G). This gets the applications started without worrying about relevant Spark parameters and helps usher in newer Data Scientists into our team with ease.
For resource intensive ETLs, we recommend overriding the default values.
sheriff is used to add overrides to default values setup via Genie.
Run Commands
These commands in sheriff essentially form a translational layer of a Data Scientist’s intent to Genie API calls.
The command run_spark helps run any Spark jobs from sheriff with ease.
It packages code dependencies and manages shipping the job off to genie with relevant parameters and tags.
To help run Spark SQL jobs, we have the command run_sql.
This command takes a sql file and packages it into a spark job that will write its results into another table on S3,
even automatically creating the Metastore definition if it does not already exist.
Additionally, we have run_with_json to help configure your options in a JSON file,
and version it separately in GitHub, rather than having a massively long command line.
Additional Tools in Babylon
Custom SparkContext
Another great time and stress reliever, is our wrapper around the HiveContext in Spark.
HiveContext, inherits from Spark’s SQLContext, and adds support for writing queries using HiveQL.
A call to our custom SparkContext class helps easily define a Spark job and use the built-in methods.
It especially helps facilitate the communication between our Spark build and the Hive Metastore.
Metastore Library
We have a Scala library called SFS3 that facilitates reading and writing to our data warehouse (S3 + Hive Metastore). It allows us to collect custom stats on our data and construct data lineage. It’s a easy-to-use API for writing and saving Spark DataFrame objects of table data. E.g.
write_dataframe(self, df, hiveschema, partitions=None, create=True,
add_partitions=False, drop_first=False)
This allows to write across multiple partitions while registering each new or updated partition with Metastore.
Table Statistics
Incorporating Broadcast joins can make jobs much more efficient,
but can also cause incredible failures if incorrect statistics are stored in the Hive Metastore.
We automate this collection of statistics via our TableAnalyzer tool.
Python Query API
For people who prefer to stay in pure Python, we have another library that hides some of the details of Spark. It allows users to write queries that, behind the scenes, utilize Spark machinery (the subject of a future blog post). E.g.
from stitchfix_data_lib import query
df = query('SELECT COUNT(*) from <table_name>', using='spark-sql')
Diagnostic Tool
And finally, we also have a Diagnostic tool that has the ability to recommend and provide pointers based on the error messages in the log output. Sample Diagnostic Reports would look like this
========= Report ==========
Script error - AttributeError: 'DataFrame' object has no attribute 'union'
========= Report ==========
Script error - import error (bad name or module not installed): No module named fire
To be continued..
Our goal to help Data Scientists have the resources they need has been a motivating factor behind our infrastructure decisions. Having a resourceful tool like Genie has proven to work well for our use case.
The next blog post in this series will explore other parts of this Spark infrastructure.
Thanks for reading.