One of the best parts of working on the algorithms team at Stitch Fix is being able to collaborate with so many talented data scientists. Working alongside peers from a variety of academic backgrounds encourages us to constantly re-evaluate our assumptions about the data and how it informs our product. This summer our community included four interns, all graduate students who are passionate about applying their academic expertise to help us leverage our rich data to better understand our clients, their preferences, and new trends in the industry. In this blog post you’ll meet the interns, who will tell you a bit about the problems they worked on and the strategies they used to solve them.
Sofía Samaniego de la Fuente
Sofía is a data science graduate student at Stanford University. She currently lives in San Francisco, but was born and raised in Mexico City. She love puzzles, running, eating, and traveling around the world.
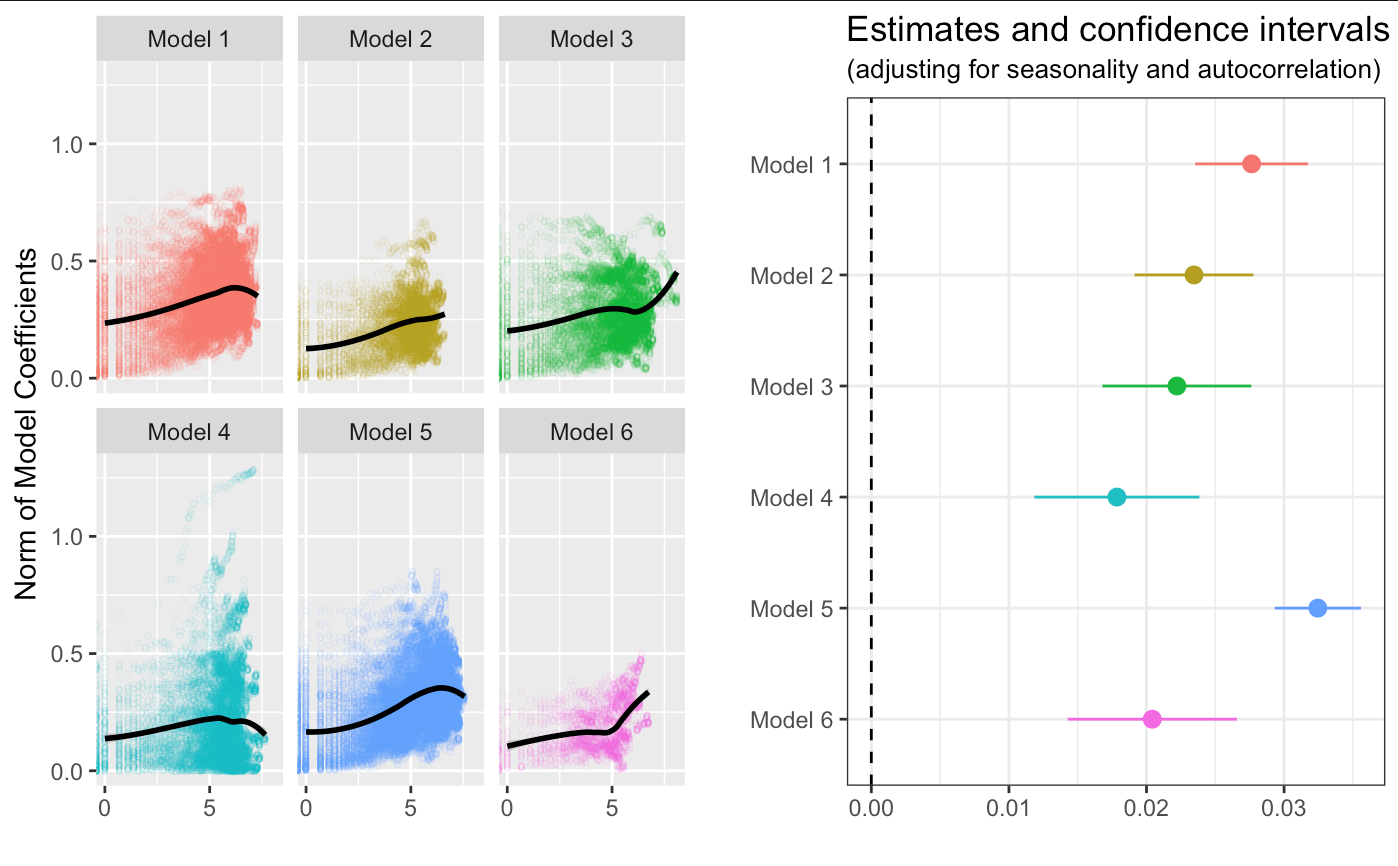
I studied how the quality of our matching algorithms changes over time. In particular, I measured how quickly matching algorithms learn about new items. To do so, I analyzed the evolution of the norm of the matching model coefficients. This is a way of measuring how much the estimates are deviating from the global mean and, hence, how much the matching algorithm is “learning” from past pairings. To make the inference more robust, I adjusted for seasonality using a cubic cyclic spline, and for autocorrelation using first differences and clustered standard errors by item.
In the left graph in the figure below, we see examples of matching algorithms that are learning at different rates, and very quickly for models 2 and 5. Nonetheless, the relationship between these variables seems to be positive across models, which in turn suggests that the number of successful matchings is increasing as we collect more data. In the right graph, we see that the effect is statistically significant. In particular, both ends of the confidence intervals for the effect of time on the norm exceed zero in all models. In other words, the learning rates of the algorithms are significantly positive!
Andrew K.
Andrew is a graduate student studying computer science in North Carolina. He was happy being in the Bay Area for the summer where he enjoyed the many opportunities to be in the outdoors.
Here at Stitch Fix I’m forecasting how fast styles will be sent out of our warehouses. This informs all aspects of inventory optimization: buying, allocating between warehouses, and retiring styles. Key to these forecasts is understanding seasonality and competition between styles. Take for instance a particular kind of gray scarf. This scarf will be sent to clients more in winter months, but less when we have many other gray scarves in stock to compete with it. We model this hierarchically. Seasonality operates at aggregate inventory levels, say determining the total demand for scarves. Competition is more granular. We consider a smaller category such as gray scarves. Each style is selected proportionally to its “propensity” score relative to that of other styles in stock in the same category.
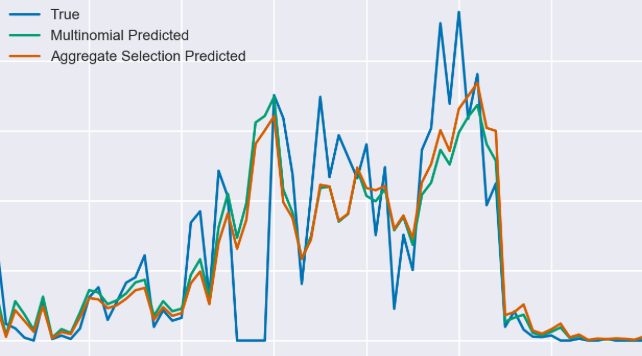 Comparing different models for selection of a style over time.
Comparing different models for selection of a style over time.
Lingrui Gan
Lingrui is a PhD student in Statistics at the University of Illinois at Urbana-Champaign where he does research in graphical models, variational Bayesian inference, non-convex optimization, and high-dimensional statistics. He loves learning new methodological, computational and theoretical concepts, and solving data science problems arising from real applications.
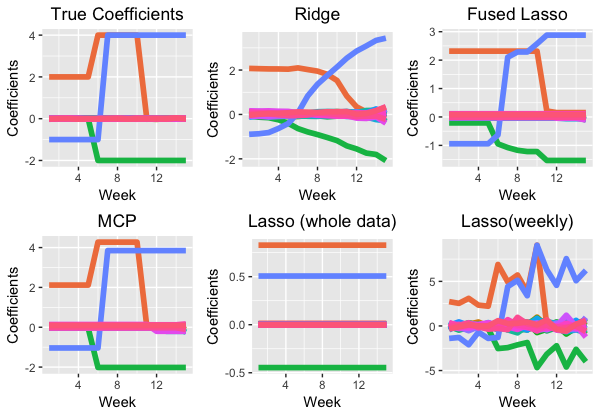
This summer at Stitch Fix, I worked with the client algorithms team to predict signup conversion using advanced machine learning algorithms. In addition to traditional classification algorithms, I used a time-varying regularized classification model to detect the variation over time of effects of features on signup conversion. The figure below shows the performance of our model in a toy example. Our model is “MCP”, which most accurately estimates the true coefficients.
I also worked on a second project with the styling algorithms team where we used a Bayesian latent factor model to extract client “interest” level from the multiple ratings they gave for each item. We will use this latent “interest” feature to improve the accuracy of our recommendation algorithms.
Richard Galvez
Richard is interested in problems on the boundary between the physical sciences and machine learning. He has a PhD in physics from Syracuse University and was a post-doctoral researcher at Vanderbilt University.
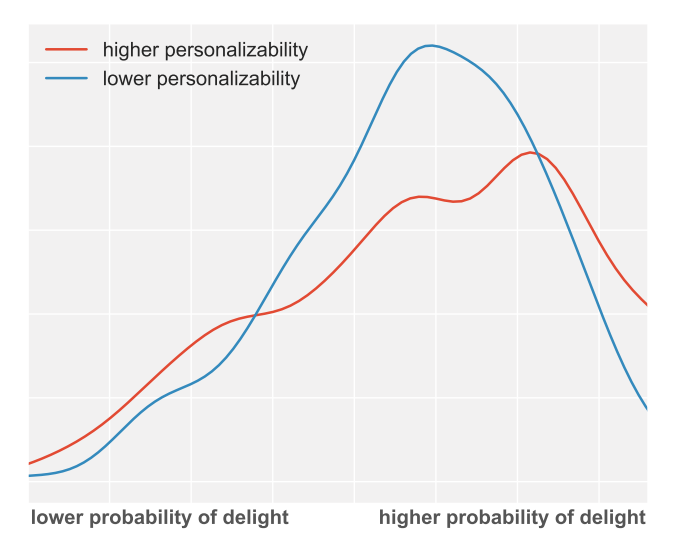
Stitch Fix prides itself on helping people find what they uniquely and truly love. My summer’s research has primarily focused on the uniqueness aspect of our recommendation system, specifically, how we can leverage our large scale data to provide each client with the pair of jeans or blouse that’s perfect for just her or him. With the goal to provide the most personalized client experience possible, my research has focused on various explorations of quantifiable measures of personalization, their variations within our client base and inventory, optimization strategies, and what large scale interactions are possible. This helps us have a quantitative way of ensuring that we really are getting the best pair of jeans to just the right person.
However, we want to do this not just for one person, but for large numbers of customers in aggregate. To this end, my work focused on the the large-scale ensemble effects of personalizability, ensuring that we truly are delivering a unique experience to each and every one of our clients, on both an individual and global scale.