Introducing Flotilla
Data scientists are not always equipped with the requisite engineering skills to deploy robust code to a production job execution and scheduling system. Yet, forcing reliance on data platform engineers will impede the scientists’ autonomy. If only there was another way.
Today we’re excited to introduce Flotilla, our latest open source project. Flotilla is a human friendly service for task execution. It allows you to focus on the work you’re doing rather than how to do it. In other words, Flotilla takes the struggle out of defining and running containerized jobs.
Using Flotilla
How exactly? You’ll start by defining a job, either in the Flotilla UI or using the REST API. All you’ve got to do is specify the code you want to run, the resources required to run it, and the docker image your code needs to run in.
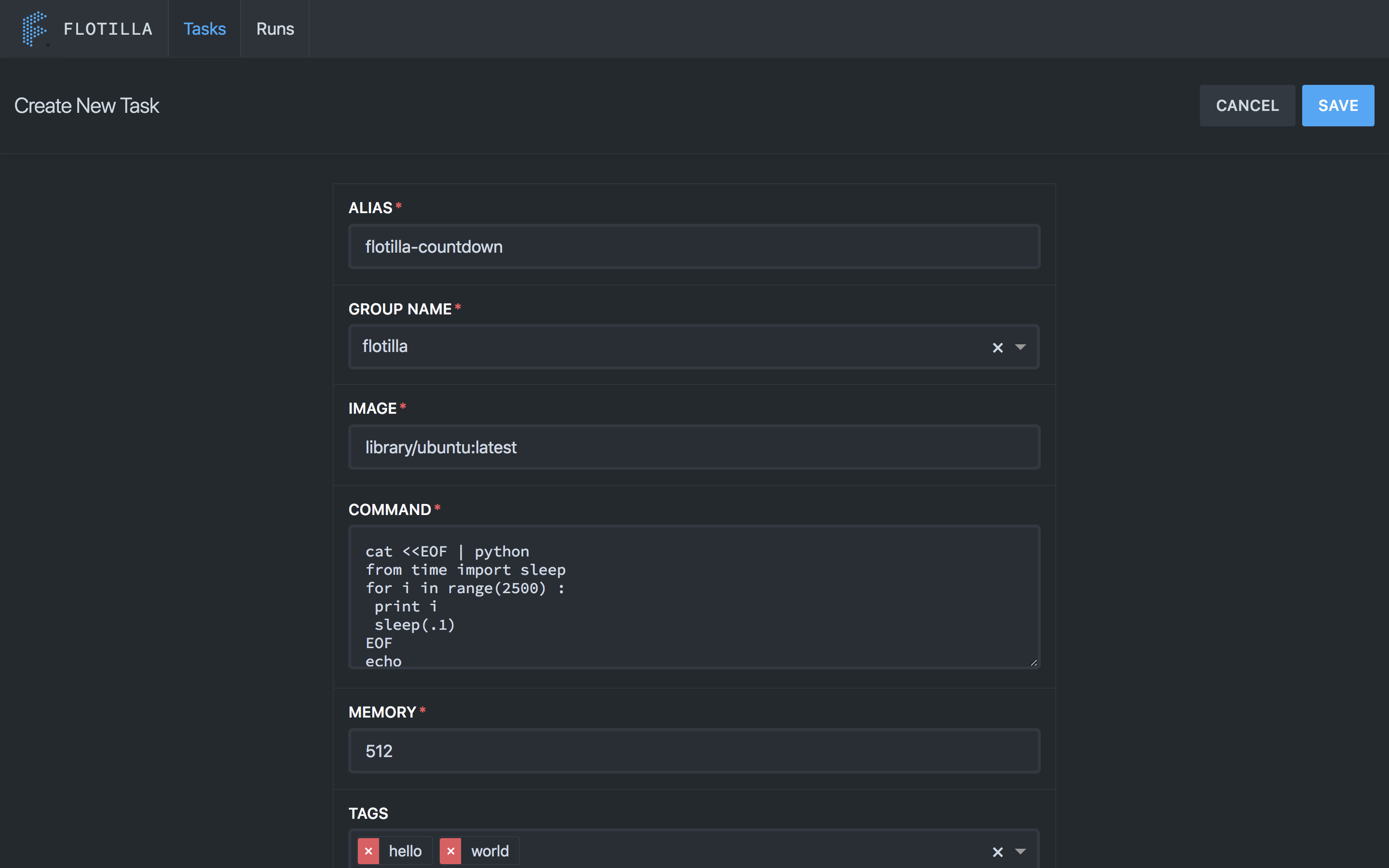
Once you’ve defined your job, you can launch it simply by telling Flotilla the cluster to run your job on and any environment variables to use.
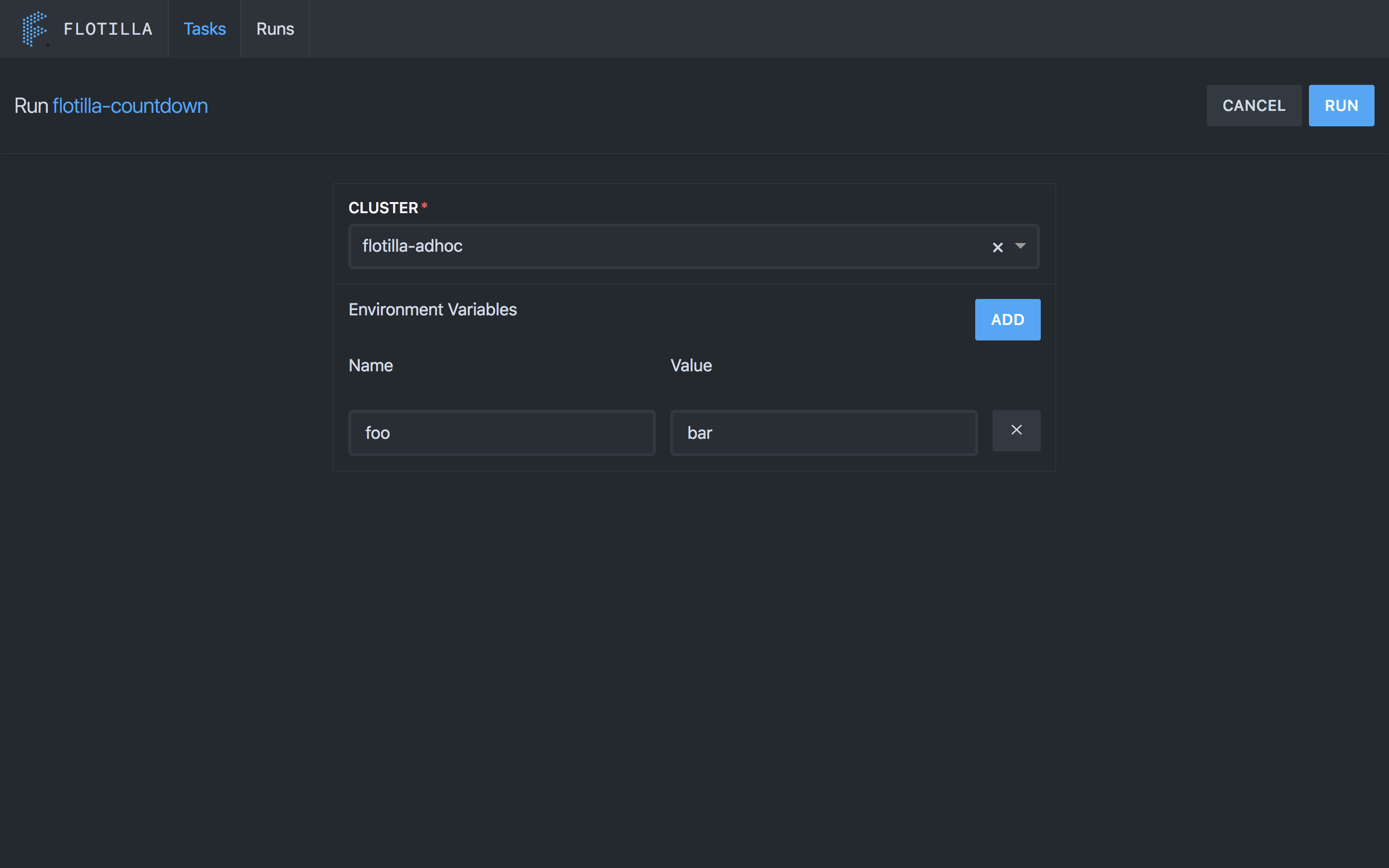
Your job will queue up until resources are free on the cluster so there’s no need to worry about what else is running. Once your job is submitted you can use the UI or API to access the state of the run and view the logs in real time. There’s even a history endpoint for viewing historical runs.
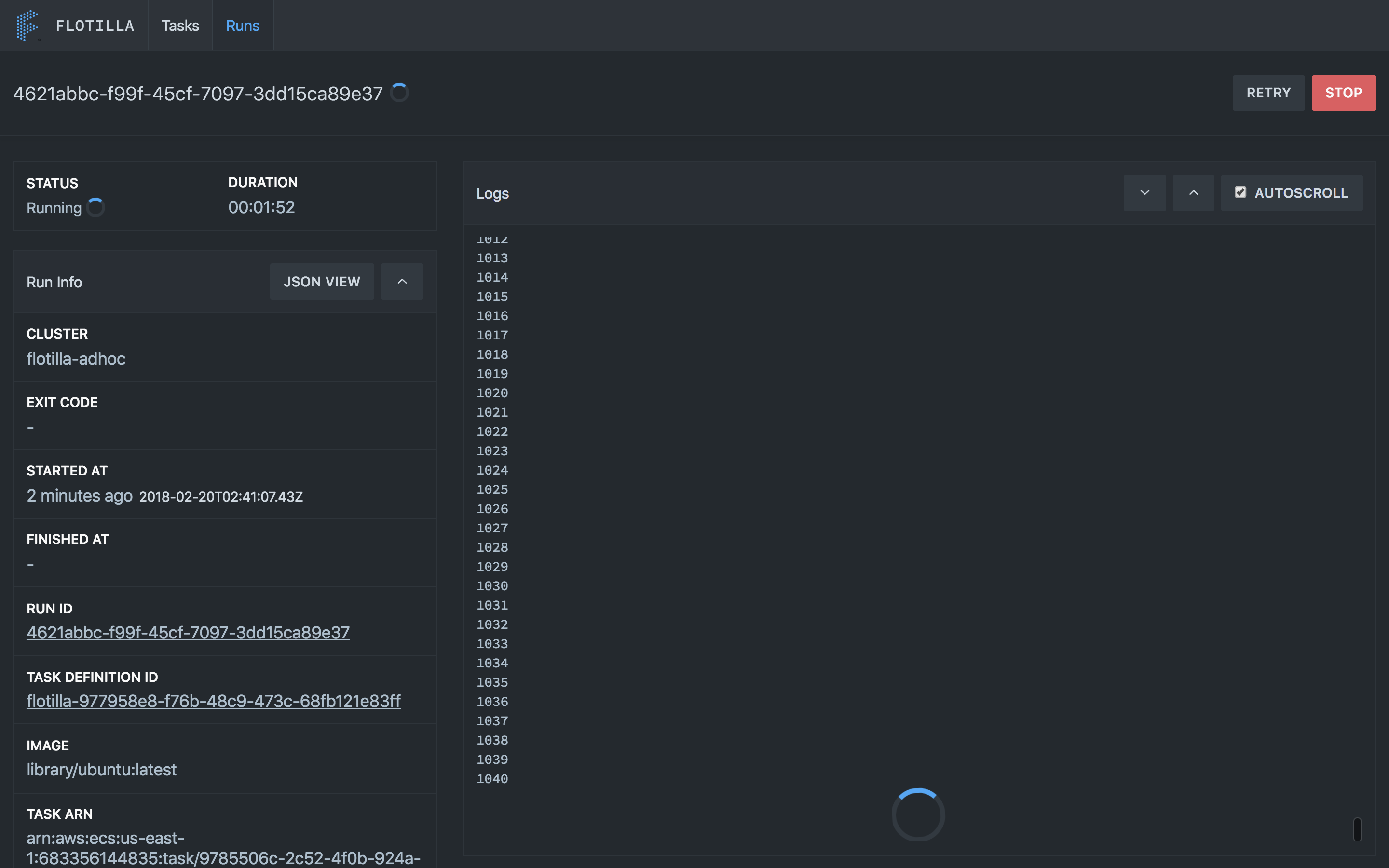
What Problems Does Flotilla Solve?
OK, so using Flotilla is easy, but why did we build it in the first place? Prior to Flotilla we were running tasks on a Jenkins cluster. This worked well early on when there were just a few users, but it scaled very poorly as our data science teams grew. Resource contention, limited isolation, and difficulties in managing infrastructure — all of these problems kept getting worse and worse. This led to a lot of frustration and lost productivity. Flotilla, with its self-service first approach, containerized jobs, and isolated run queues, has all but made these problems disappear.
How?
Containerization is made possible by running each job in its own Docker container. Isolation and scaling is managed by allowing data scientists to define their own execution clusters, which automatically get their own run queues. Jobs running on one cluster will never interfere with jobs on another.
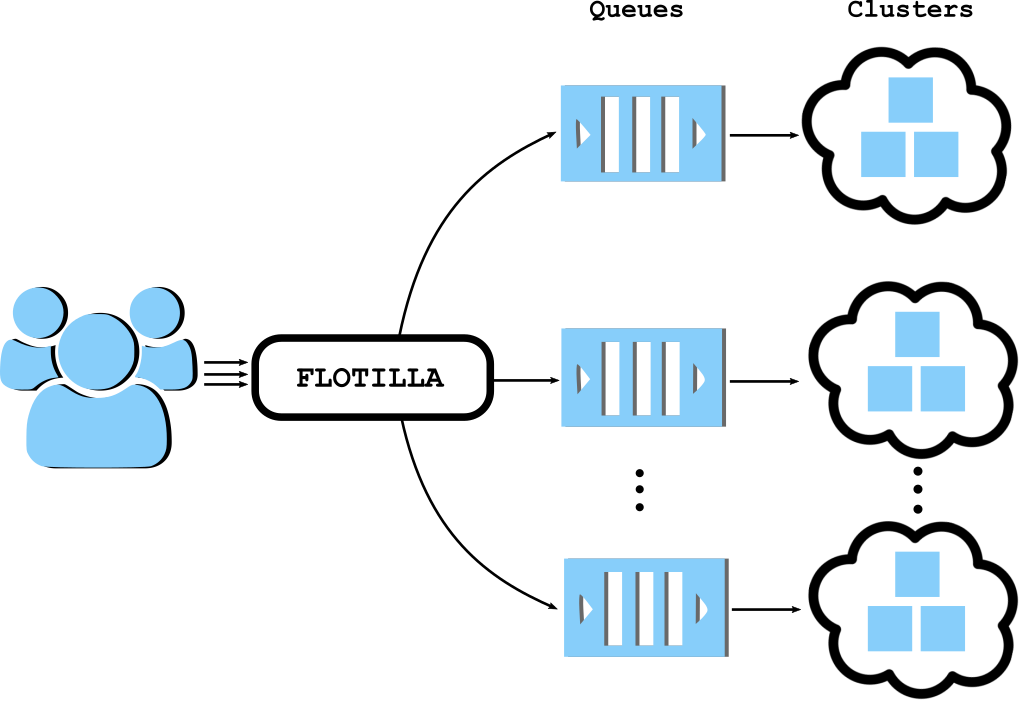
Flotilla uses Amazon Web Services’ Elastic Container Service (ECS) clusters by default, so any cluster created there is available for use. Soon we plan to open source a cluster management service, which simplifies the process of creating and maintaining execution clusters.
History
At Stitch Fix we’ve been using Flotilla in production for two years now and have run well over two million jobs since its inception. These jobs range from very short duration tasks like sending email alerts, to more complex tasks like etl and model training and large multi-day tasks that create graph structures. For us, the greatest benefit of Flotilla is that data scientists can own their own work all the way from ad hoc tasks and manual iteration to scheduled jobs in production.
Philosophy
But why create a new service? Aren’t there other solutions for this? Sure, there are tools like Jenkins for defining and running jobs. There are also cluster-managing and resource-scheduling systems like Nomad, Docker Swarm, Kubernetes, Mesos, and ECS. These systems are great, but they are very complex and general-purpose. Our data scientists are not engineers and can be more productive day-to-day with higher-level streamlined functionality.
Without Flotilla, the typical solution here is to either force your data scientists to learn the complicated systems, internalize best practices, and essentially become engineers or to hire a team of production engineers.
There are significant trade-offs with both of the above options. The first option means the scientists must spend time dealing with details of the execution system, rather than exercising their hard-earned domain expertise to provide value and insight. The second option is more common in practice but creates process and communication overhead. It also takes the ownership and accountability out of the hands of the folks who care about it the most (the data scientists) and shares it with a group of production engineers who have differing incentives and motivations.
Flotilla is a third option. A new way forward. It doesn’t replace these complex cluster-management and resource-scheduling systems, but instead leverages them and bridges the gap between those systems and the data scientists.
Open Source
Flotilla is written in Go and uses Amazon Web Services’ ECS as its primary backend execution engine. We hope to add additional execution engines like Kubernetes and Mesos with community involvement. We’ve also included a full React-based UI as part of the release.
Flotilla has been a huge unlock for us, and we’re excited to release it so that other teams can benefit from it as well. It only takes about 5 minutes to get set up. Just clone the repo on github here and follow the quick-start guide. Full documentation is available on the landing page here. We’d love to have collaborators and see GitHub issues, pull requests, or related tools. Stay tuned for future open source projects for execution, cluster management, and Docker image creation.