Note: we understand that there are more important topics in the world given that we're in the midst of a pandemic, and we wish for everyone to remain safe & healthy. We're continuing to publish blog posts in the hope that they provide a sense of connection and a signal of continuity — while it's difficult to think beyond the day, together, we will get through this.
“Uh oh.”
Frightening words to overhear — even more frightening to involuntarily utter. It means that something has gone wrong: an important table deleted, corrupt data written, perhaps something even worse.
One way to avoid mistakes is to hire only unicorns who can type quickly and infallibly with that magical horn.
For the rest of us, errors will happen despite our best efforts and intentions, and it’s helpful if there are structures in place that enable seamless recovery. For realistic data science/engineering teams, it’s possible to develop structures & processes that reduce the incidence of mistakes,[1] and to build technology that reduces the harm of errors when they inevitably occur.[2]
All of these processes & technological approaches are helpful in principle, but doing everything can slow down development time considerably, so being judicious about what safety mechanisms to invest in can make a big difference. Although common sense mistake-avoidance measures are no brainers for any technical org (including ours!), we have found that investing in a few safety net systems that enable data scientists and engineers to recover from mistakes yields value both in the obvious ways (quicker recovery) and in the peace of mind that comes from knowing that mistakes can be easily rolled back.
The Hive Meta-metastore is part of our recovery mechanism, and once we built it we realized it had other benefits as well.
Hive Metastore… and Hive Meta-metastore
The Metastore
At Stitch Fix, the Hive Metastore is how we keep track of the relationship between logical databases, tables, and columns, and the underlying data (which happens to be stored on S3). Spark, Presto, and our internal table readers and writers all understand location and type information via the Hive Metastore. (If we used Hive, it would understand these things via the Hive Metastore, too.)
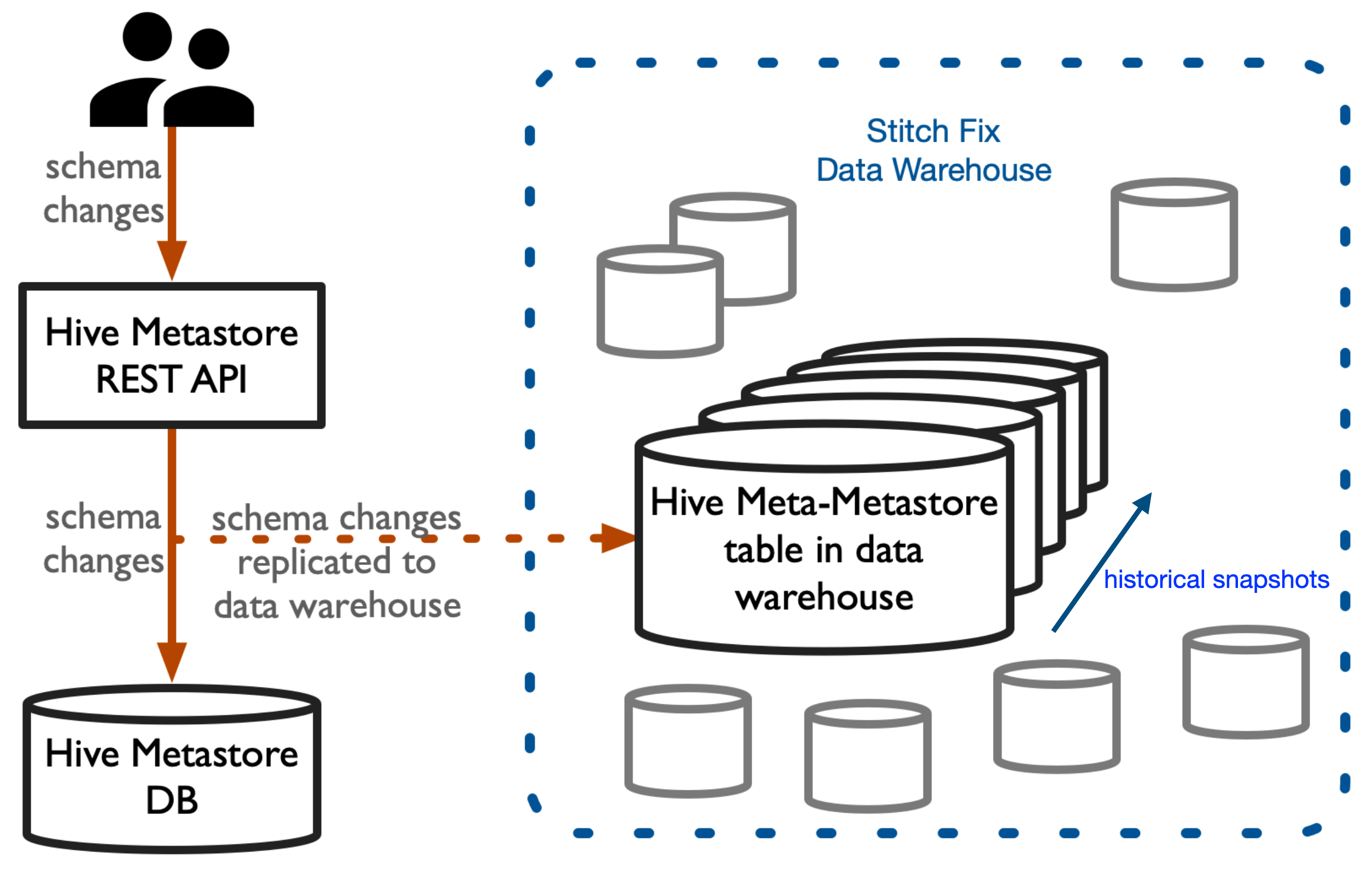
The Hive Metastore itself is a SQL database that stores all this information about locations of data and types of columns. The problem is that it only stores current state; once a change occurs, the previous state is gone. One safeguard against this is that data scientists don’t interact with the underlying database itself; rather, they use a python client that makes HTTP requests to a REST service that interacts with the underlying database, and this python client also emits a Kafka message on our “data highway” with every request (which gets stored in our data warehouse). So we keep a record of every Hive Metastore change and could in principle reconstruct past states via a series of diffs, similar to how Git can follow a series of diffs to get to any past state. However, building a version control system for schema changes, while a laudable goal, is a big project.
The Meta-metastore
If the metastore is where we store data about data, the meta-metastore is where we store data about the data stored about the data. A much simpler solution than building version control for schema changes: just snapshot and store the Hive Metastore SQL database at regular intervals (daily, hourly, whatever you need for your use case). However, the SQL database is intended for machine usage, not human usage, so to make the snapshots more data-scientist friendly, we transform to approximately this schema:
snapshot_ts | db_name | table_name | column_name | datatype | comment
We have hundreds of databases, tens of thousands of tables, and hundreds of thousands of columns, all stored in this simple Hive Meta-metastore table. Each snapshot is stored in its own snapshot_ts partition.
Also, for quick access to the current state of the Hive Metastore in a more user-friendly format than the underlying SQL database, we have a version of this table that has the same schema except without the snapshot_ts column.
Errors with schemas
Now, back to those “uh oh”s: Have you ever accidentally dropped a table, or corrupted its schema,[3] and wished you could restore it to its correct state?
In the days when all table schemas were individually defined in DDL files, you could usually use the DDL file to restore the table. You corrupted the DDL file when you corrupted the table? No worries — if you were clever, you had kept the DDL file under version control and could restore it to the correct version.
But these days, you might have a system with automatic type inference, making it easy to automatically create and modify schemas; that ease might make it even less likely that you designed a mechanism for versioning your schema. You could be left without a record anywhere of what the schema was back when it was correct. Also, schema errors can be particularly insidious and difficult to catch if they are only slightly different from the correct ones. (In fact, if a disgruntled person wanted to be nasty on their way out the door, making such subtle changes to schemas might be an effective way to wreak havoc … recovering from an unlikely hypothetical event like this would have been quite stressful pre Hive Meta-metastore.)
Benefits of the Hive Meta-metastore
Recovery (self-service recoverability!)
First, we of course have standard, best-practice disaster recovery systems (S3 versioning, regular backups of the Hive Metastore SQL database, etc.).
But building the Hive Meta-metastore made it easy for us to build self-service recovery tools that enable an individual data scientist to recover from user or program error for a single table or a small set of tables. A table’s schema is wonky today but was good last week? Yes, we can check the Kafka messages to see what request led to the corruption … we can also just restore the schema to its state when it was correct, so we built a Python library for making this process easy. If a table called 'important_table' in database 'prod' was good on January 9 but is corrupted now, data scientists can restore with a function as simple as this:
restore_table(
database='prod',
table='important_table',
restore_from_date='2020-01-09'
)
Discovery
Data scientists like exploring data. But they need to find it first. The Hive Metastore is data about data. This allows data scientists to find the data they are interested in. The Hive Meta-metastore is data about our data about data. It allows data scientists to find the metadata they are interested in. By storing this as data (in our data warehouse), we’ve allowed data scientists to explore it with the same tools (SQL, Python, R, etc.) as they use to explore any other data.
Because of this, an unanticipated benefit of the Hive Meta-metastore is that it’s easy to discover what data we have.[4] Curious which production databases contain columns where someone has added a comment that includes the word 'deprecated'? Just run this query:
SELECT
db_name,
table_name,
column_name,
comment
FROM metametastore_db.metametastore_current_state
WHERE db_name LIKE '%prod%'
AND LOWER(comment) LIKE '%deprecate%'
In fact, just this morning, a data scientist asked what’s the most columns we have in any table. This query gives the top 3:
SELECT
database_name,
table_name,
COUNT(*) AS num_columns
FROM metametastore_db.metametastore_current_state
GROUP BY database_name, table_name
ORDER BY COUNT(*) DESC
LIMIT 3
And, just the other day, a data scientist said “That’s weird. When did that column switch from an int to a string?” With the meta-metastore they can find out:[5]
SELECT
MAX(snapshot_ts) AS most_recent_int_snapshot
FROM metametastore_db.metametastore_history
WHERE database_name = 'the_database'
AND table_name = 'the_table'
AND datatype = 'int'
As it turns out, in day-to-day work, the “discovery” usage is far more common than the “recovery” usage.
Wrap-up
Imagine trying to walk a tightrope suspended high above the city street by being really careful. Now imagine doing the same thing with a safety net just a few feet below you. Which situation causes your palms to sweat? This illustrates the emotional difference between introducing processes to prevent mistakes (by being really careful) versus introducing tools for self-service recovery from mistakes (the safety net). Providing a feeling of safety via self-service recovery allows people to learn quickly through experimentation without stress; the Hive Meta-metastore is an example of such a system.
While the Meta-metastore was built to enable self-service recovery from mistakes, we have found that the information it contains is very valuable to discover data sources. Since this information is surfaced as a database, it’s easy for data scientists to write simple (or complicated!) queries over the meta-metastore using SQL. Want to know the names of all columns that store information indexed by product_id? It’s a simple query over the meta-metastore. Want to know all such columns that have been added since you last looked two months ago? That’s also just a query over the meta-metastore.
On those rare instances when we have a corrupted schema and jobs are failing, the easy recovery made possible by the Hive Meta-metastore is worth its weight in unicorn horns.
What’s the upshot for you?
Some aspects of our Hive Meta-metastore project could probably generalize pretty directly to your org. Most obviously, if you have a Hive Metastore, you might want to consider building a Hive Meta-metastore. The good news: it’s easy! If you can write a for loop, you can make a Hive Meta-metastore — just regularly loop over all your databases and tables and record the column schema information.
Even if you don’t have a Hive Metastore, we hope you consider the benefit of building self-service recovery tools in general. We had actually been musing about the idea of a Meta-metastore for several weeks in the fall of 2016, when one day one of our key tables had a substantial schema error. Data scientists scrambled and fixed the error. The next day, we sat down and built the initial version of the Meta-metastore in an afternoon. Don’t make the same mistake we did! Think ahead about what areas of your org could benefit from lightweight self-service recovery tools, and build them before stuff hits the fan.
“Meta-meta Blues”
One of our former data scientists (Steven Troxler) was so enamored of the Meta-metastore that he wrote a song about it.
Notes
[1] E.g., code review, unit tests, integration tests, blameless postmortems, etc. ←
[2] E.g., RAID storage, version control, retry mechanisms, fallback systems, speculative execution, etc. ←
[3] Our infrastructure defines schemas at the table level. Some designs define schemas at the partition level, where schema corruption may be less of a problem. ←
[4]
If you’re familiar with standard SQL, the current view of the meta-metastore might sound a lot like the INFORMATION_SCHEMA.COLUMNS table. You can think of the full meta-metastore as being similar to a regularly snapshotted history table of “INFORMATION_SCHEMA.COLUMNS” (in quotation marks because Hive/Presto/Spark don’t actually have an INFORMATION_SCHEMA.COLUMNS table). The self-service recovery tools that we’ve developed on top of the meta-metastore, however, enable more recovery than you could achieve with a history table of schema snapshots, since we retain data for a short period of time after it’s no longer pointed to by any active Hive Metastore tables — in other words, if you accidentally “delete” a table, you can easily recover it if you realize this shortly afterward (without having to touch AWS versioning backups).
←
[5]
And note that INFORMATION_SCHEMA.COLUMNS cannot answer this kind of question.
←