Thank you to all the 2020 summer interns that worked with the Stitch Fix Algorithms team. For the first time, the internship program was fully remote, but that hasn’t stopped them from working on impactful projects. This post summarizes some of the projects they worked on. We appreciate all your contributions and insights!
Natural Language Processing with Client Feedback and Request Notes
Justin Cho, PhD student in Computer Science at University of Southern California
This summer, I worked on the Merchandise Algorithms team. One of our responsibilities is to help decide what to stock in Stitch Fix’s inventory. We receive feedback in the form of unstructured client comments, and we wanted to better understand how clients felt about the styles we were sending them. To do this, we used recent natural language processing (NLP) models to summarize client comments.
In order to encode the semantics of individual comments, we transformed free-text comments into numerical representations with a Sentence BERT model and clustered them using HDBSCAN. Leveraging these clusters, we identified the most representative comments and how frequently they occur, enabling us to better understand how our clients feel about the items we send them.
This pipeline proves to be useful for featurizing comments and incorporating them into downstream algorithms. The comments contain a lot of qualitative and nuanced information that is not captured by structured data. By identifying clusters related to certain attributes of interest and aggregating comments within them, we are able to create additional features that can help improve our recommendation models.
Lastly, we apply this featurization pipeline to other natural language data at Stitch Fix, including the request notes that our clients provide when requesting a Fix. This enables us to discover shifting trends in what our clients request over time. This information helps us identify the right inventory that will delight our clients in the future. See the figure below for an illustration of what kind of data we can derive from this pipeline.
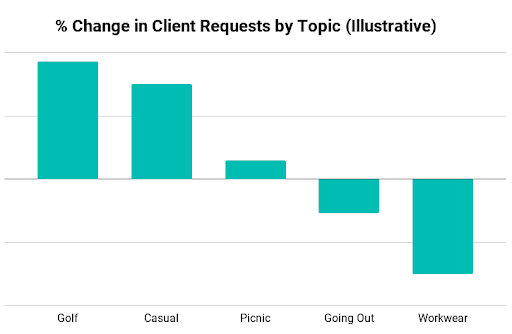
Recommendations Based on Client-uploaded Images
Ziwei Fan, PhD Student in Computer Science at the University of Illinois at Chicago
When it comes to fashion, it’s difficult for a client to describe their preferences in words; a picture is a far more effective vehicle. The Stitch Fix Inspiration board allows clients to save photos of various fashion outfits to a board that they can share with their stylist. To help inspire the client, a recommendation system provides suggestions of other images that identify with the client’s style. Clients can also upload their own photos of outfits from pinterest, selfies, etc. We want to be able to provide recommendations based on these pins as well. The goal is to extend our recommendation system to be able to recommend new content based on these images as well.
Developing a recommender system for such images is challenging because we obviously do not have any previous interaction data associated with these client-upload images (i.e. the cold start problem), and we have to figure out what is in the image in the first place.
The first step is object detection. A single image may contain several fashion items - pants, shirt, shoes, etc. Next, for each object, we programmatically search in our catalog for similar items, taking the closest matches. For each item retrieved we use existing models to predict how well the client will like it. We then distill down the set of items using our understanding of the client’s preference to provide fresh recommendations.
When clients upload an image they are either conveying that they like the outfit, or, that they like a particular piece of clothing that is a part of the outfit. If the former is the case, we want to average the scores of objects in the image. In the latter case, it is more appropriate to take the maximum of the scores. Through backtesting on a separate dataset, we found that the second approach leads to better recommendations. As a result of this project, Stitch Fix now has the ability to recommend new outfits based on images the client uploads to their board. We’ll continue to develop this capability to provide value to our clients.

Surrogate modeling for long-term outcomes
Madhav Kumar
Firms frequently test different policies involving customer acquisition, discount promotions, recommendation systems and many others using field experiments. The experiments are typically run for periods ranging from a few days to a few weeks during which customers are exposed to one, or more, policies. After the experiment is over, the firms observe the actions of consumers exposed to different policies and estimate the treatment effects to compare the relative efficacy of the policies. Subsequently, the firms weigh the costs and benefits of different strategies and make a decision on whether to institutionalize the policy with the expectation that it will improve long-term profitability.
While this evaluation procedure is grounded in a sound statistical approach, it is laden with many heroic assumptions. For instance, most of the policies that are tested are designed to improve long-term profitability and/or customer satisfaction. However, the analysts do not observe the long-term outcome (e.g., customer life-time-value over periods of 1+ years) when evaluating the results of the experiment. Hence, the policies are compared based on short-term measures with the assumption, and hope, that the observed short-term improvements will be reflected in long-term outcomes. For example, online retailers with very low purchase rates may resort to up-funnel metrics such as intent-to buy or add-to-cart as proxies for actual purchases.
During my internship at Stitch Fix, we implemented a system that overcame this limitation. We used surrogate modeling, prevalent in medical literature and recently popularized in economics, where we combined multiple short-term metrics to learn a surrogate index using historical observational data. We then predict the long-term outcome in the experimental sample using the short-term metrics and estimate the treatment effects on the predictions. The figure below shows an illustrative surrogate model.
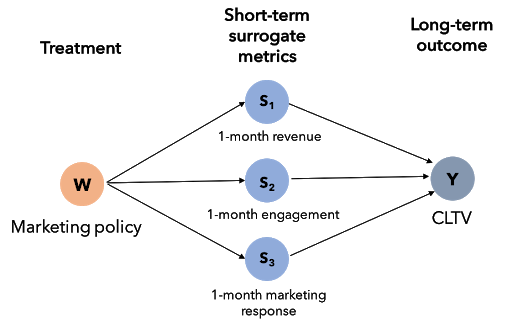
We started by collating historical experiments run at Stitch Fix that were at least a year old and therefore we can observe their long-term outcomes. These experiments span a myriad of policies, ranging from updates to payment channels to recommendation algorithms. For each of these experiments, we compiled observational customer data that was at least two years old - one year to first train the long-term model and the second year to validate it with the realized long-term outcome. In the historical observation data, we calculate the same short-term metrics that we are going to observe in the experimental data, such as 1-month purchase rate and 1-month engagement. We used these metrics, along with customer-level control variables, to predict the customer life-time value. We then used the fitted model to generate predictions on the experimental sample where we observe the short-term metrics and the control variables. We then estimate the average long-term treatment effect by comparing the predictions for the customers in control vs. the predictions for those in treatment. We repeat this exercise for each experiment under consideration and compare how the predictions performed with respect to the observed long-term outcomes. Overall, we found that not only was the model able to estimate the treatment effects accurately, it did so with higher precision than a simple average of the long term outcome of interest.
Subsequently, we implemented the system in Stitch Fix’s experimentation platform where different teams can quickly generate a report to see their policy’s expected long-term impact on customer life-time value.
Prentice RL. Surrogate endpoints in clinical trials: definition and operational criteria. Stat Med. 1989;8(4):431-440. doi:10.1002/sim.4780080407