At Stitch Fix, our mission is to transform the way people find what they love. As data scientists, we think about this a lot, and have built a host of tools to helps us do just that: our core recommendation algorithm, our set-based recommendations, our latent style spaces, and many other models, we frequently utilize client feedback to construct representations of our merchandise to effectively recommend the most appropriate items. Sometimes, the ‘best recommendation’ isn’t merely a matter of ‘best for you’; it can include important contextual elements.
Take, for example, choosing a restaurant for the evening: your favorite restaurant of all time might be that delicious Ethiopian place downtown, but you were just chatting with your friends about tacos! If you’re looking for a dinner recommendation, it may help to add to the request ‘mexican food’. In this context, the recent conversation might heavily weigh on your restaurant choice tonight. Personalized ranking is an extremely important aspect of our business, but this style of recommendation system is commonly referred to as query-based recommendations, or sometimes personalized search.
Many of our clients love to tag us in social media posts about the looks they’re excited about, and give us permission to share their looks as inspiration for other clients as they’re shopping with Stitch Fix. In this case, each featured ‘community inspiration’ image we show you serves as a ‘query’ to make recommendations that are both personalized to you and relevant to the image, so that you can ‘#stealTheLook’. This is query-based personalized ranking, so let’s dig in (and maybe later dig into some tacos 🌮)!
Understanding images

A “community inspiration” image features a client with clothing that may or may not have been originally purchased from Stitch Fix. We understand the unstructured image via the objects within it. Specifically, we wish to put these images in terms of data we already understand: our catalog.
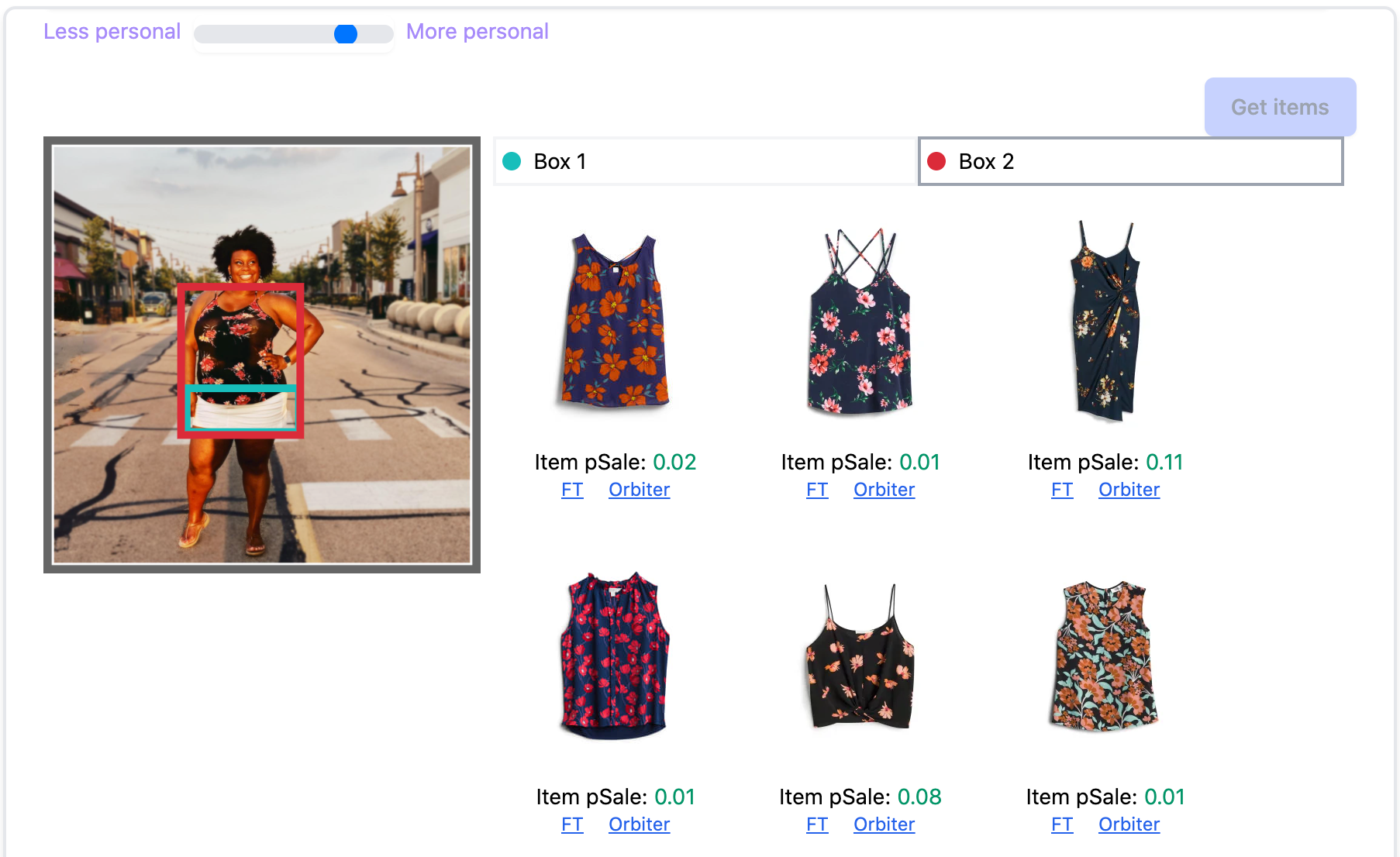
We use off-the-shelf computer vision tools to identify different clothes in the image and map them to specific pieces in our own catalog which we’ll call ‘anchor items’. For example, in the animation, we detect the shirt and the jeans, then find a few anchor shirts and anchor jeans similar to those in the image from our catalog. We generally find between 10-60 anchor styles depending on the number of distinct pieces detected in the image.
With each image mapped to a collection of detected objects, and each object mapped to a collection of known styles, we now have a representation of the image as a collection of collections of known styles. The devoted MultiThreaded blog reader will remember that we have an existing representation for our items in a high dimensional latent space that helps us understand how items and client style relate (c.f. understanding latent style). Our set of sets of anchor styles becomes a set of sets of latent embeddings, which can be further aggregated and summarized. Importantly, these embeddings are in a space shared with clients (call that space \(C\) for clients; we’ll come back to that).
Recommending images
With this pool of imagery in a structured form, we can start asking who to show what as a recommendation problem.
From the last section, we have a representation of each image as a set of sets of embeddings. In terms of the photo in the animation above, we have a set of embeddings for the shirt and a set of embeddings for the jeans. First, we’ll average the anchors’ embeddings for each object to get a single shirt embedding and a single jeans embedding.
It’s worth noting that averaging here helps us with errors in the computer vision pipeline. For example, a pair of sweatpants sneak into the results for the jeans, but as long as we’re mostly right, within a small enough neighborhood where averaging makes sense, the final embedding averages out a decent amount of error.
Next, we’ll take advantage of the fact that these embeddings are in a space shared with clients (thanks, latent style team!). We use an existing model to score each object embedding against the client embedding, giving us a per-object score: one for the shirt-client combination, and another for the jeans-client combination. To combine these into one score, we have had the best luck with simply taking the max. In the example above, the shirt score is 0.8 and the jeans are 0.4, so the whole image gets a score of 0.8.
To recap, we combine anchor item embeddings to get an “object” embedding, then score the image based on how much the client will like their favorite object in that image.
The image we choose to show is the “query” for our query-based recommendations.
Shopping images
Now that we have images we think the client will love, let’s find related items in our inventory to shop! In most cases, we want to go beyond recommending the anchor items–not only do we need to respect client preference and inventory availability, we want to show a diverse set of items to maximize the chances our clients will see something that’s great for them.
First, we return to the anchor items and search for similar available inventory. We compute similarity in one of our handy merch representation spaces[1] that combines both image-similarity and the latent client-based \(C\) embeddings used in previous sections (call this new space \(H\) for hybrid). The combination balances how similarly items look as well as how similarly clients respond to them (note: these are frequently very different!). We use the hybrid space to find the k-nearest-neighbors for each anchor, respecting size preferences and previous feedback. Each candidate \(i\) has an anchor-to-candidate distance, which measures relevance to the image (call it \(d_i\) for, well, distance).
We’re racking up a lot of candidates now! An image is many objects. An object is many anchors. An anchor has many neighbors. We’ll use our favorite math tool of composition[2] to see that an image has many-many-many neighbors. We’ll flatten the set of sets into a single set of candidates now, to keep the indexing clean. If there are duplicates, we keep the minimum distance for it. For instance some particular pair of jeans in inventory are an okay match for one anchor (\(d_i = 3.14\)), and a better match for another anchor (\(d_i = 2.71\)), so we keep the closer \(d_i = 2.71\) and deduplicate.
We’re not done yet! Stitch Fix is obsessed with personalization; so far the image is personalized to you, but we also need to personalize the item recommendations. We’ll return to \(C\) (client) space to get the client-candidate affinities the space was built for (call them \(a_i\) for affinity).
Let’s take stock of what we have so far:
- nearest neighbor search gives us very many candidate items \(\{i \in 1...\textrm{So Many}\}\) with minimum distance measures \(d_i\) to anchor items.
- each item respects the client feedback and size preference
- those items have affinity scores \(a_i\) which predict how much the client will like it.
We need to select a subset of the above items which we think the client will really love, but will still be appropriate for the context of the inspirational image. We do a very simple multi-objective ranking[3] that takes into consideration both distance and affinity: a weighted combination. Our client-anchor score is simply \(s_i = \alpha \times (1 - d_i) + (1 - \alpha) \times a_i\). We learn \(\alpha\) experimentally[4].
Finally, we ensure some diversity in the output via computing top-\(N\) per category with respect to a few item features and our multi-objective score \(s_i\).
Conclusion
While this may all feel very bespoke, it’s important to take a step back and think about the architecture of this solution. If we are able to take an arbitrary query(of any content type) and map it into a collection of anchor items, we can use the above tools to serve query-based personalized recommendations! Even more excitingly, each of the latent spaces that we’ve stitched together are models that have strong investments at Stitch Fix, and so we can take advantage of all of their improvements! By utilizing both personalization and similarity models we can make great recommendations that make sense in context.
Given a general recommendation problem where you want to utilize context, you should look to:
- map that context to a representation where you can measure relevance of items to the context
- select items that are highly relevant
- measure the affinity between those items and the client.
Attributions
The Latent Style space is built by our Core Representation Learning Team. The personalization affinity scores are a model built by our Styling Recommendations Team. Image and item similarity services are built by our Shop Recommendations Team. This work was led by the Client Recommendations Team. If any of these problems interest you, check out our open roles!
Thank you to Javad Hashemi, Dan Marthaler, and Sven Schmit for feedback on this article.
References
[1]↩ For a deep dive into similarity search in latent spaces, check out FAISS. Note that we do not use FAISS, but it provides an excellent overview of the subject.
[2]↩ One of the authors has a past life in category theory, which he has tried to explain to the other author many times. The latter author only really remembers it’s all about composition.
[3]↩ For an excellent discussion of a deeper multi-objective problem, consult Taking your business to new (Pareto) frontiers by our colleagues!
[4]↩ A bandit approach could be useful here, but we use an interleaving design.