This post showcases what a Platform and DS team can accomplish collaborating at Stitch Fix.
Creating dataframes is easy, but managing the codebase to do so can become difficult and complex. When a data science team reached out for help to bring more structure to the problem, we worked together to build Hamilton (which we’re also open sourcing today)! This post is an accompanying backstory + introduction.
Background
A common task of a Data Scientist is to produce a dataframe (a.k.a. feature engineering) that will be used as input to create a model. I’m sure for most readers of this blog the following would be a familiar sight:
df = load_some_data('location/SQL query')
df['column_b'] = SOME_CONSTANT * df['column_a']
df['column_c'] = df['column_b'].apply(a_transform)
# … some more feature engineering
model = fit(df)
For simple domains and models, the above code will likely not get too difficult to manage. However, if you’re in a domain such as time series forecasting, where a lot of the columns you’re creating are functions of other columns[1], the code for this can get quite intertwined and complex.
The Problem
Now picture the case in which the above code helps create some type of model. These models are successful and critical to the business, and need to be updated and used on a weekly basis. For example, it’s doing some critical operational forecasting. No problem, the above code lives in a script that can be executed by a scheduled task. To facilitate creating and curating better models, a team is formed around this business critical task, they follow best practices in maintaining things in working order, e.g. the code is version controlled, so that any changes can be reviewed, any breaking changes can be reverted, etc.
Now fast forward five years and there has been just enough team growth to keep up with the expanding business. What do you imagine happened to the above codebase? It’s likely gotten more complex; accommodating business changes, new models, new features. But is it a nice kind of complex, the one that you’d like to work with on a day in and day out basis? Likely not. It hasn’t grown convoluted out of malice, or bad software engineering practices, it’s just complex because every time something needs to change, the dataframe (df in the example) needs to be touched. This leads to a few problems:
- Column (i.e. feature) dependencies are hard to determine.
- For example, if I create column a, that is subsequently used by column c, d, and then those are in turn used as inputs to create other columns, those in turn are used as inputs, etc. there isn’t an easy way to determine these dependencies unless you read all the code. Which in a large code base is difficult.
- Documentation is hard.
- If there are many lines of code doing:
df['column_z'] = df['column_n'] * log(df['column_o']) + 1Then it’s hard to place documentation naturally.
- If there are many lines of code doing:
- Unit testing is hard.
- Similar to the documentation example, how do you unit test inline dataframe transformations easily?
- You need to execute and understand the entire script to get any columns (i.e. features).
- This can become a burden on development if you need to compute the entire dataframe when you only need a portion of it. E.g. you’re developing a new model that doesn’t need all those columns… let me go make some coffee…
In application, this means that a new person joining the team has a lot of ramp up to do, and tenure is directly correlated to the amount of time it takes to debug an issue, or add a new column (feature). The learning curve to productivity grows steep and long; each new modification exacerbates this curve – after years of this kind of development, the learning curve looks more like The Dawn Wall[2].
Some of you might be reading this and wondering – “what on earth is wrong with these people?” – obviously the solution is to put more into functions. Functions can be documented, and unit tested. We don’t disagree with you there. Functions are great! However, organizing code into functions is merely a tool, and does not provide adequate guard-rails against the issues we saw above. For example, what do you pass as input to these functions? The whole dataframe? Specific columns of the dataframe? In all likelihood, this still means that you have to execute the entire script to get anything. It also doesn’t solve the issue of knowing what columns are used and unused, and what their relationships are with each other.
The Stitch Fix Approach
At Stitch Fix, the Forecasting and Estimation of Demand (FED) team is responsible for operational forecasts that the business makes decisions with. As part of their workflow they require large complex dataframes to train and execute their models with. Naturally, they encounter every one of the problems we described above. Thankfully, now they don’t have to solve this problem on their own.
One of the functions of the Algo Platform team at Stitch Fix is to help build libraries, tools, and platforms to enable Data Scientists to move faster in their work. The Algo Platform team is organized into sub teams that focus on different capabilities required for data science to connect back with the business. Each sub team has a lot of latitude in creating solutions. Our Model Lifecycle Team, which as their goal is to streamlines model productionization – which includes streamlining feature creation – tackled this problem.
Before going further, we first want to mention that, while we explored a variety of offerings, we did not find any open-source tooling that would dramatically improve our capability to solve the aforementioned problems. Second, we’re not solving a big data challenge here, so a base assumption is that all data can fit in memory[3].
The Result: Hamilton
To tackle the FED’s problems, a collaboration was formed between the FED and the Model Lifecycle teams, and a project was born to help rethink their code base. Out of it came Hamilton, a python micro framework for generating dataframes[4]. This framework was specifically designed to address the pain points that arose from creating dataframes(housing thousands of engineered features and years of business logic) to be used as inputs to time series forecasting. The main “trick” to Hamilton is how it changes the paradigm of dataframe creation and manipulation to handle this painful complexity. More on that below.
With the advent of Hamilton in November 2019, Data Scientists on the FED have exclusively written specially shaped python functions to produce their dataframes. As mentioned earlier, concise functions help solve problems with unit testing and documentation, we’re not breaking new ground here. However, how does one resolve the issue of tracing dependencies within the dataframe, and selective execution? Easy; we build a Directed Acyclic Graph, or DAG for short, using the properties of how the python functions are shaped.
You: Wait, I’m confused? Explain!
Instead of having Data Scientists write column transforms like:
df['COLUMN_C'] = df['COLUMN_A'] + df['COLUMN_B']
Hamilton enables Data Scientists to express them as functions similar to the following[5]:
def COLUMN_C(COLUMN_A: pd.Series, COLUMN_B: pd.Series) -> pd.Series:
"""Documentation"""
return COLUMN_A + COLUMN_B
The name of the function equates to the name of the column. The input parameters are the names of the input columns (or other input variables) that the function depends on. The function documentation string[6] becomes documentation solely for this piece of business logic. The body of the function does computation as normal. For most intents and purposes, the output should be either a series, or a dataframe, but this isn’t a hard requirement.
Note the paradigm shift! Instead of having Data Scientists write code that they subsequently execute in a massive procedural tangle, Hamilton utilizes how the function is defined to create a DAG and execute it for Data Scientists. With this approach column relationships and business logic are documented and unit tested easily.
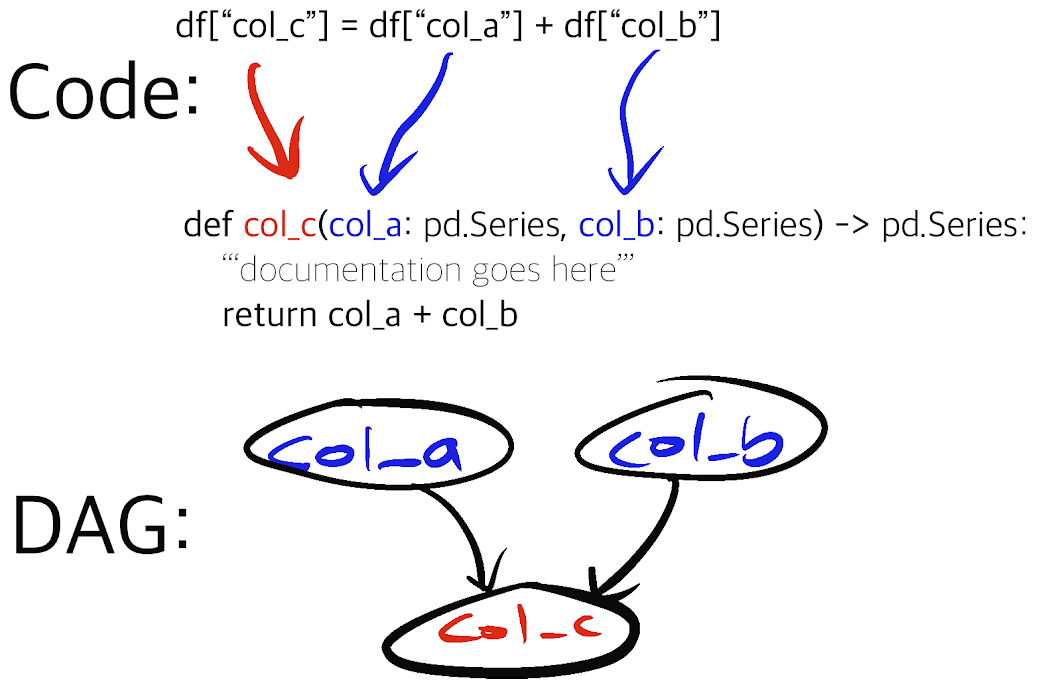
Example showing code before, code after, and the DAG constructed.
With column definitions at parity with functions definitions, we then make use of python’s builtin inspect[7] module to create the DAG of all these declared functions. This enables us to determine which parts of the DAG are required to compute any given node, i.e. column. This in turn enables us to pare down the set of inputs and executions that are required given a list of desired output columns.
A Data Scientist can now create their desired dataframe in two simple steps: initialize and execute. The inner workings of these steps are neatly abstracted by the framework. All the Data Scientist needs to specify for the initialization of the DAG are some starting configuration parameters and the python package/module to crawl for function definitions. To execute, they need only specify which columns they would like in the final dataframe.
Functional Example 1:
import importlib
from hamilton import driver
initial_columns = { # load from actuals or wherever
# this is our initial data we use as input.
'signups': pd.Series([1, 10, 50, 100, 200, 400]),
'spend': pd.Series([10, 10, 20, 40, 40, 50]),
}
# module to import functions from
module_name = 'my_functions'
py_module = importlib.import_module(module_name)
# create the DAG
dr = driver.Driver(initial_columns, py_module)
# determine what we want in the end
output_columns = ['signups', 'avg_3wk_spend', 'some_column']
df = dr.execute(output_columns, display_graph=False)
Being able to represent column relationships as a DAG has a few other benefits:
- With type hints on the functions, we can compile the DAG before running it to do basic type checking and validation.
- We can visualize the DAG. This is a great way to quickly understand complicated relationships - for new and veteran team members alike.
- We can perform other graph analyses, e.g. what can we delete? Unused columns would be represented as orphaned DAGs for example.
- By using a DAG to logically model function execution, this leaves open the possibility for us to compile execution for different execution environments. E.g. Spark, or to properly take advantage of multiple cores on a system, etc.
That’s it. It’s pretty simple and relatively lightweight.
In case you’re still not convinced, here’s a testimonial from a Data Scientist at Stitch Fix that on boarded onto the FED team:
I’ve previously onboarded at an organization that dealt with multiple layers of information dependency. The “data product” was a result of years of multiple authors adding layers without systematic examination for potholes like circular references. Because of that, the product was a terribly fragile product and knowledge transfers took place through a series of ad-hoc trial and error by a new member; they run into an issue, ask their supervisor for clarification, then they are handed an opaque explanation and workaround which then gets propagated through a game of telephone to the next person (the mechanics of solution is propagated, but the reason behind the solution is not). In my own experience, the ah-ha moment did not occur until I doggedly followed the thread of information and built a dag on my own.
Having had that experience, onboarding a data product that already had a graph structure to embody the complex dependency was a delight; chief among its many benefits is that the product is amenable to other generic analysis approaches for graphs. Moreover, because of the abstraction that separates dataframe structure from quantitative specification, it helps a new person to process the information without having to have a priori domain knowledge, since dependencies are clearly specified and functions are simple and concise.

(this is a reference to Chevy's "real people not actors" ad -- the DS here is a real person, not an actor wink 😉)
Learnings
Making Hamilton code simpler to maintain
As work progressed on porting Data Science code to use Hamilton, it became clear that there was room to improve the way we define functions for use with Hamilton. Here are two examples we think the reader will find most interesting:
-
How do we handle conditional execution? Do we want a single function with if else statements, or multiple functions for each individual case that depends on some input? E.g. Stitch Fix has multiple business lines that are modeled independently, however we want to share code where possible. In the case where each business line might require some different logic, how do we best handle that while keeping the code simple and easy to understand and follow?
Here’s a contrived example. The point here is that the logic for each business line could grow arbitrarily complex and require different inputs, thereby muddying the dependency structure, and bringing back problems we were trying to solve with Hamilton in the first place.
Contrived Example 1:
def total_marketing_spend(business_line: str, tv_spend: pd.Series, radio_spend: pd.Series, fb_spend: pd.Series) -> pd.Series: """Total marketing spend.""" if business_line == 'womens': return tv_spend + radio_spend + fb_spend elif business_line == 'mens': return radio_spend + fb_spend elif business_line == 'kids': return fb_spend else: raise ValueError(f'Unknown business_line {business_line}') -
How do we keep similar logic between transforms DRY? Repetitive functions that differ by a single value made the code repetitive and unnecessarily verbose. E.g. setting indicator variables for holidays, or when special events occurred, or the redesign of the website, or launch of new products.
Contrived Example 2:
def mlk_holiday_2020(date_index: pd.Series) -> pd.Series: """Indicator for MLK holiday 2020""" return (date_index == "2020-01-20").astype(int) def us_election_2020(date_index: pd.Series) -> pd.Series: """Indicator for US election 2020""" return (date_index == "2020-11-03").astype(int) def thanksgiving_2020(date_index: pd.Series) -> pd.Series: """Indicator for Thanksgiving 2020""" return (date_index == "2020-11-26").astype(int)
Luckily, we’re dealing with functions, so a common tactic we’ve employed to help with the above cases is to create decorators. These work as syntactic sugar to help keep the code more concise and enjoyable to write. Let’s describe the decorators that improve the above examples.
Avoiding if else statements with @config.when*
In the “contrived example 1” above, we had a bunch of if else statements based on business line. To make the
dependencies clearer we define three separate functions and decorate them with @config.when to delineate the condition
under which that definition applies.
@config.when(business_line='kids')
def total_marketing_spend__kids(fb_spend: pd.Series) -> pd.Series:
"""Total marketing spend for kids."""
return fb_spend
@config.when(business_line='mens')
def total_marketing_spend__mens(business_line: str,
radio_spend: pd.Series,
fb_spend: pd.Series) -> pd.Series:
"""Total marketing spend for mens."""
return radio_spend + fb_spend
@config.when(business_line='womens')
def total_marketing_spend__womens(business_line: str,
tv_spend: pd.Series,
radio_spend: pd.Series,
fb_spend: pd.Series) -> pd.Series:
"""Total marketing spend for womens."""
return tv_spend + radio_spend + fb_spend
When we construct the DAG we only keep the functions that meet the filtering criteria specified in the decorator. The
filtering criteria comes from the configuration/initial data provided at instantiation (functional example 1, variable initial_columns).
This enables us to selectively include or exclude functions based on some configuration parameters.
You might have also noticed the __ suffix indicator in the function names. We want the target column names to stay the
same across configurations, but a function can only have one definition in a given file, so we are forced to name it
differently. Imposing the decorator + dunder naming convention in the framework, we can conditionally define the
underlying function of an output column; if we detect the suffix in a function name, the framework knows to strip it,
thus creating the output column name and definition appropriately.
Using @config.when helps to ensure that we avoid complex code, and can catch bad configuration at DAG construction time.
For example, in the previous incarnation if we provided an incorrect business_line value, we wouldn’t know about it
until code execution time (if ever!). While using @config.when, if we pass in an incorrect business_line value we’ll
error out when requesting that output column since there’s no such way to satisfy that request.
Reducing code to maintain with @parametrized
Using Hamilton naively can make simple functions feel unnecessarily verbose: one line to define the function, another
few for documentation, and then a simple body. To reduce this feeling, we can instead create a single function to share
code across multiple column definitions. What enables us to do this is to decorate this function with @parametrized to
tell Hamilton what columns it represents (or rather, all of the arguments this function can be called with). For example,
we can rewrite “contrived example 2” the following way:
# we define the input here
SOME_DATES = {
# (output name, documentation): value to pass
("mlk_holiday_2020", "MLK 2020"): "2020-01-20",
("us_election_2020", "US 2020 Election Day"): "2020-11-03",
("thanksgiving_2020", "Thanksgiving 2020"): "2020-11-26",
}
@function_modifiers.parametrized(parameter="single_date", assigned_output=SOME_DATES)
def create_date_indicators_(date_index: pd.Series,
single_date: str) -> pd.Series:
"""Helper to create an indicator series from a single date."""
return (date_index == single_date).astype(int)
In addition to being more concise, we prefer this to “contrived example 2” for two main reasons:
- If we change logic (e.g. in our example how date indicators are created), we only have to change it in one place.
- If we have more of these to create, it’s only a single line that needs to be added.
Bonus reason we like this decorator:
- Documentation! Even though we’re only adding a single line, we can still properly account for documentation, this ensures each function is still documented.
Here we only covered two of many decorators that Hamilton comes with. The other decorators we have created help with other contexts, which arose from other learnings we’ve had with the framework.
Code reviews are simpler
Simplifying the code review process was not an intended goal when creating Hamilton. It just so happens that when you force tighter encapsulation of business logic into functions, it is far easier to review changes.
For example, rather than having to trace through changes that touch a lot of files and lines of code, because logic was not that well encapsulated, things are much simpler with Hamilton. Forcing Data Scientists to write clear functions that explain what inputs they require and what outputs they create is a simpler, more grokkable artifact for a reviewer to comprehend. This has had the result that code reviewers are more efficient and less errors make it through the review process.
Conclusion
Hamilton is a framework that helps a team of Data Scientists manage the creation of a complex dataframe in a shared code base by writing specially shaped functions. By handling the how, Hamilton allows Data Scientists to focus on the what. It was the result of a successful cross-functional collaboration between the Model Lifecycle and FED teams at Stitch Fix, and has been running in production since November 2019. We think our novel approach to creating a dataframe works well for our context here at Stitch Fix and have enjoyed sharing our experience with you.
Finally, we’re excited to announce that we’re open sourcing Hamilton!
It’ll hit the spot for you if you have to maintain
data frames with hundreds (even thousands) of columns and all the data can fit in memory[8].
Just pip install sf-hamilton
to get started. For more details on getting started with Hamilton and how to use it,
we refer you to the README. If you do take a look at Hamilton, we’d be interested
in your feedback or ideas for contributions; see the github issues section
for the ideas we’re curating! We’ve also created a discord server as another way to engage with interested persons.
P.S., as always, we’re hiring.
P.P.S., we would like to thank the reviewers and copy editors Albert Yuen and Sven Schmit for their feedback. Many thanks!
Footnotes
[1]↩ Columns are features in our parlance. For the purpose of this post we’ll stick to describing features as columns in a dataframe.
[2]↩ The Dawn Wall is the name of an ascent route up El Capitan in Yosemite. It’s very steep and difficult to climb.
[3]↩ This is a constraint we’re looking to remove.
[4]↩ The framework is more powerful than just creating dataframes, but this is its first application.
[5]↩ Since writing functions with Hamilton is a slight increase in verbosity, we do have decorators to help keep code DRY. Keep reading to see some examples.
[6]↩ Did you know that with sphinx, a python documentation tool, you can surface this function documentation easily too? We have a post merge job that builds sphinx docs from this code to help surface it better.
[7]↩ The TL;DR on the inspect module is that it allows you to access the names and signatures of functions very easily.
[8]↩ Right now Hamilton executes on a single machine, so you’ll need to be able to load the data into memory for it to operate. Luckily services like AWS enable you to easily scale up the machine used, so you can get pretty far with this approach.