Our team’s favorite interview question to ask potential platform engineers is what defines your ideal Machine Learning platform, and how would you build it? By asking this, we aim to dive into the applicant’s thought process around the abstraction they would build to represent a model. Would they exert control over the type, shape, and approach of the model in exchange for a more operationally simple system? Or would they let data scientists run wild, creating any kind of model one can dream up?
At Stitch Fix, data scientist autonomy and quick iteration are paramount to our operational capabilities—above all, we value flexibility. If we can’t quickly iterate on a good idea, we’re doing our clients (and ourselves) a disservice. Aside from requiring production models to be written in Python, anything goes.
Our question often turns into a lively debate on the merits of different platform architectures. At Stitch Fix, we’ve concluded that what we initially perceived as a trade-off is not one at all: a machine learning platform can be operationally simple, framework-agnostic, and intuitive at the same time. We know because we’ve implemented such a platform at Stitch Fix and have achieved widespread adoption and success.
In this blog post, we’re going to share our initial design considerations for the platform we built, present the API data scientists use to interact with it, and detail its capabilities.
Designing for Stitch Fix
Requirements
What does it mean for a tool to be operationally simple, framework-agnostic, and intuitive? We required the following:
- Self-service management: It should be operationally simple for a data scientist to do anything they want with their models. They should not have to go through the platform team to productionalize a model; instead, the platform should present an intuitive, straightforward way to plug their models back into the business and track their performance.
- Separation of concerns: It should be intuitive for a data scientist to manage their models in production. We want them to achieve scalability and reliability for free while spending the bulk of their time and efforts on the methodology and implementation of their models.
- Models as a black box: We have no intention of dictating the methodology of a data scientist’s workflow. Thus, we aim to be framework-agnostic for both model inference and training.
- Less-is-more API: The more we can automagically derive from the environment, code, etc. about a model, the less a data scientist has to handle when deploying that model. While this can be controversial (the wrong magic is worse than none at all), too many degrees of freedom will make the product less appetizing to adopt.
Build or Buy?
We’re not the first people to build a high-caliber ML platform, and we certainly won’t be the last. In fact, we met the maintainers of various open-source products (MLFlow and ModelDB in particular) and were quite impressed. However, we ultimately decided to build our own for several reasons.
Leveraging Valuable Infrastructure
The Stitch Fix data platform is sophisticated and highly-tailored toward the use-cases of our data scientists. Over the years, data scientists at Stitch Fix have gotten comfortable running batch jobs, writing and maintaining microservices, and storing and managing large quantities of data, all with a few simple commands. Building on top of our current infrastructure gave us a leg up. Instead of adopting an entirely new set of tools, we can easily migrate and tap into existing testing and monitoring ecosystems.
Customizing Model Indices
The majority of platforms we considered assumed a specific shape for storing models. This took the form of experiments—each model was the next in a series. In Stitch Fix’s case, our models do not follow a linear targeting pattern. They could be applicable to specific regions, business lines, experiments, etc., and all be somewhat interchangeable with each other. Easy management of these dimensions was paramount in how data scientists needed to access their models.
Pivoting Towards our Use-Cases
When we started drafting our requirements, we had a rough sense of how the platform was going to be used in the future. That said, with a rapidly evolving business, we had limited foresight as to how our requirements would change over time. We needed to be able to pivot as we explored our space of users, so locking in to a specific platform product was not advantageous.
Building our own platform did not, however, preclude taking advantage of external tooling. By investing in the right abstractions, we could easily plug into and test out other tools (monitoring/visibility, metrics/analysis, scalable inference, etc.), gradually replacing pieces that we’ve built with industry standards as they mature.
Taking this all into consideration, we chose the difficult (but ultimately rewarding) path of building it ourselves! We’ve named our platform the Model Envelope. The data scientist puts the model in an envelope, gives it to the platform, and we handle the rest.
The API
We designed our API to be as intuitive as possible. We did this by reducing degrees of freedom for data scientists while making it easier to do what they want. This helped (a) lower the cognitive burden on users and (b) enable higher levels of abstraction. Within the platform we designed, we chose to limit what the data scientist needed to get started to two initial actions:
- Write and save a model as a simple Python function
- Specify a set of tags for the model
The tags take the form of string key/value pairs, allowing a data scientist to index the model and query for it later on.
This is easy to see with the following bare-bones example:
import model_envelope as me
import pandas as pd
def predict_ltv(features: pd.DataFrame) -> float:
# DS code to predict client lifetime revenue from a set of features
# Some DS code, perhaps storing state, perhaps part of a class
pass
me.save_model(
query_function=predict_ltv,
name="client_ltv_model",
description="Predicts client LTV from a set of features",
tags={
"business_line" : "womens",
"region" : "US",
"canonical_name" : "client_ltv"
},
api_input=training_data # Loaded earlier, a pd.DataFrame
)
And it’s as simple as that! In this case, the data scientist also specifies sample input data (e.g., the training data), so the Model Envelope can learn the shape of the function.
While data scientists only need to provide a few pieces of information, we have the capability to store and derive a lot more. In particular:
| The environment (Python dependencies) | Derived from the Python environment on which the model was trained |
| Training data/output stats | Derived from the specified API input/output |
| Non-standard Python dependencies (custom modules) | Passed in if needed |
| Additional query functions | Logged through an API call with the client |
| Metrics | Logged through an API call with the client |
This is the essence of the less-is-more API. Data scientists focus on the minimal components they need to get a model out the door, making it easy to iterate on and reason about their model management workflow. The platform can then derive enough information to fill out an expressive interface for a model. This is the hub of what we built—a model artifact database and metastore that enables the platform to handle the rest. Let’s dive into some of the spokes.
Capabilities
The representation of a model we described above enables easy deployment, tracking, and iteration in production. Throughout the next sections, keep in mind that capitalizing upon the following capabilities requires minimal additional code to be written—the majority is configuration and UI-driven.
Online Inference
As Stitch Fix developed a personalized direct-buy shopping experience, the importance of online inference grew significantly. When a client logs into Stitch Fix’s website (or app), every aspect of their experience is now optimized by algorithms. They are served by dozens of models, all powered by microservices. The platform we built ensures these services can deploy and scale reliably with the push of a button.
To deploy a model to production with the Model Envelope, a data scientist can do one of two things:
- For iteration or ad-hoc development, click the deploy button in the UI
- For continuous delivery (CD) of models, set up automatic deployment
The vast majority of models at Stitch Fix are retrained weekly, if not nightly. Thus, option (2) is the preferred choice (after an initial iteration period). To set up a CD routine for their models, a data scientist specifies a set of rules, primarily consisting of a tag query. When a model with tags matching this query is created or updated, the platform deploys that model to a specified URL. The convenience and simplicity of this ensures that the vast majority of Stitch Fix’s models utilize CD—removing the human from the model deployment process entirely. Furthermore, this makes Continuous Integration easy. A deployment rule can require a model to have a tag (say passes_tests) to be set to "true", allowing a data scientist to decouple the saving, testing, and shipping of a model to production with a simple configuration.
While the interface is straightforward, it hides a plethora of infrastructure under the hood. Behind the scenes, the platform does the following:
- Listens for model updates to the database on all tag queries
- Launches a job to deploy a model service. This job:
- generates the code for a microservice to execute a model
- builds a docker image (using the model’s specified Python dependencies)
- deploys within our internal microservice infrastructure
- sets up monitoring and alerting, enabling the platform team to manage this service
As the platform team has control over the shape of the service, each looks effectively the same as any other. We manage hundreds of automatically generated production services, with almost no additional effort. Each has its own API, a unique set of Python dependencies, and runs the specified model artifact. All services automatically scale up to meet traffic demands and are closely monitored by the platform team’s on-call rotation. The result is operational simplicity for both parties. The data scientists cede production support to the platform team, which in turn manages a tranche of reliable and highly homogenous services.
Batch Inference
While Stitch Fix functions largely as an online shop, batch inference plays a critical role in our workflows. We use it to:
- Snapshot a model’s predictions for debugging/downstream use
- Run analysis over a model’s predictions (backtests, etc.)
- Serve cached predictions as an optimization
Executing batch predictions efficiently at scale is a challenging technical problem. It requires in-depth knowledge of (in our case) Spark, broadcasting of a potentially large model, and management of the results. While our data scientists are up to the task, they’d all be doing essentially the same thing: running a large map operation over a set of input data. Since we have all the information we need to run a model, we offer this capability for free.
To do this, we provide a set of batch job operators that work with Stitch Fix’s in-house job-orchestration system (built on top of Airflow). In order to run one of these operators, data scientists have to provide:
- A tag query to determine which model to run
- Input tables with features in the data warehouse
- A table to write to in the data warehouse
- The standard parameters for a batch job (chron specs, dependencies, etc.).
Behind the scenes, the platform handles:
- Downloading and deserializing the latest model that matches the tag query
- Setting up a Spark driver/cluster
- Broadcasting the model artifact to the Spark executors
- Loading the input data, running the model, and saving the output data
And, again, it’s as simple as that! Data scientists only have to think about the where and when to deploy a model in a batch, but not the how. The platform handles that.
Metrics Tracking
Data scientists use metrics/hyperparameters to answer a wide variety of questions. Some of these include:
- How has my model’s training/validation performance varied over time?
- How has the input data changed over time?
- What happens to metric a if I modify parameter b?
- How does the distribution of results for one model compare to the other?
Prior to the introduction of the Model Envelope, any tracking of models was done on an ad-hoc basis. Data scientists utilized custom dashboards, bespoke metrics storage, and ex post facto reports to gain visibility into the performance of their models. With the unifying index of model tags, it is much easier for a data scientist to slice and dice model data to answer all of these questions. All they have to do is log a metric:
import model_envelope as me
training_data = load_training_data(...)
actuals = load_actuals(...)
model = train_model(...)
envelope = me.save_model(...)
predictions = model.predict(training_data)
envelope.log_metrics(
# Log a scalar metric named training_loss
training_loss=calculate_training_loss(predictions, actuals),
# Log a more structured metric named roc_curve
roc_curve=calculate_roc_curve(predictions, actuals)
)
Note that they’re not required to do this during training; they can do it in a completely decoupled process.
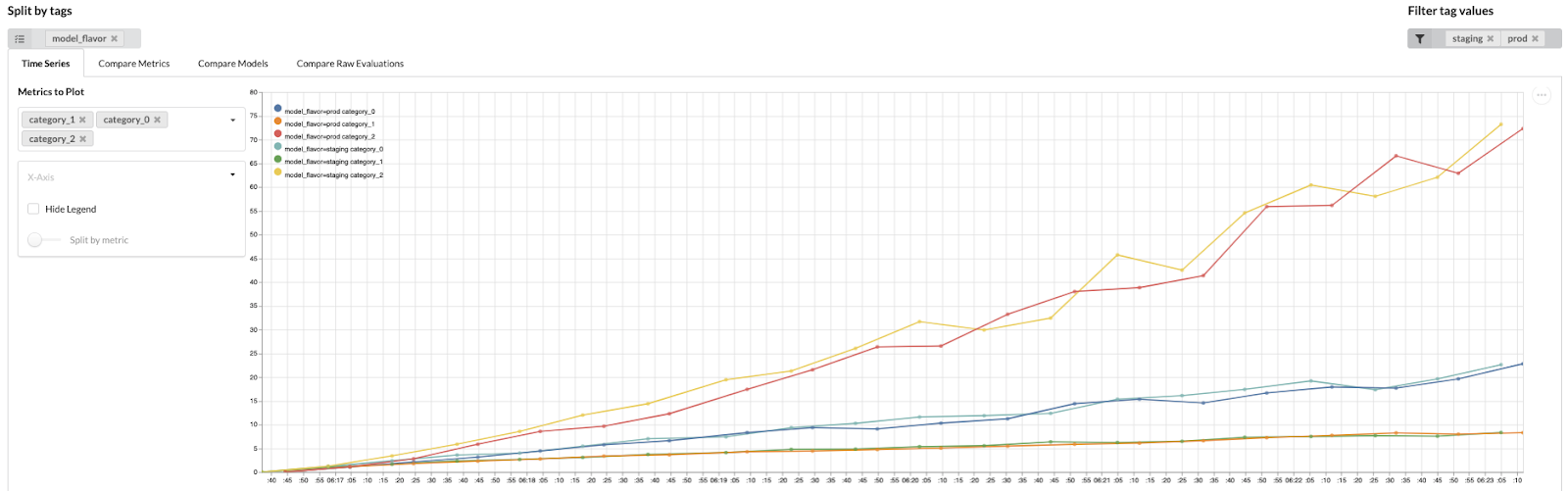
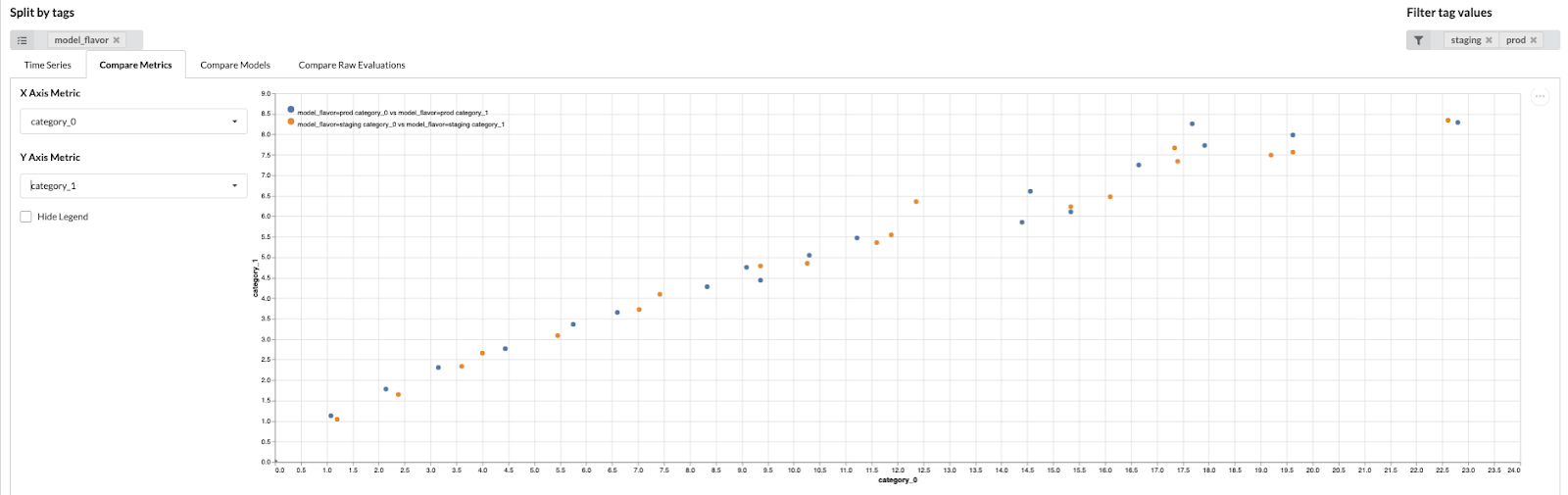
Data scientists then log onto a tool we call the model operations dashboard, select a set of tags to query, and select a method of visualization, one of…
Time Series
Compare Metrics
Compare Models
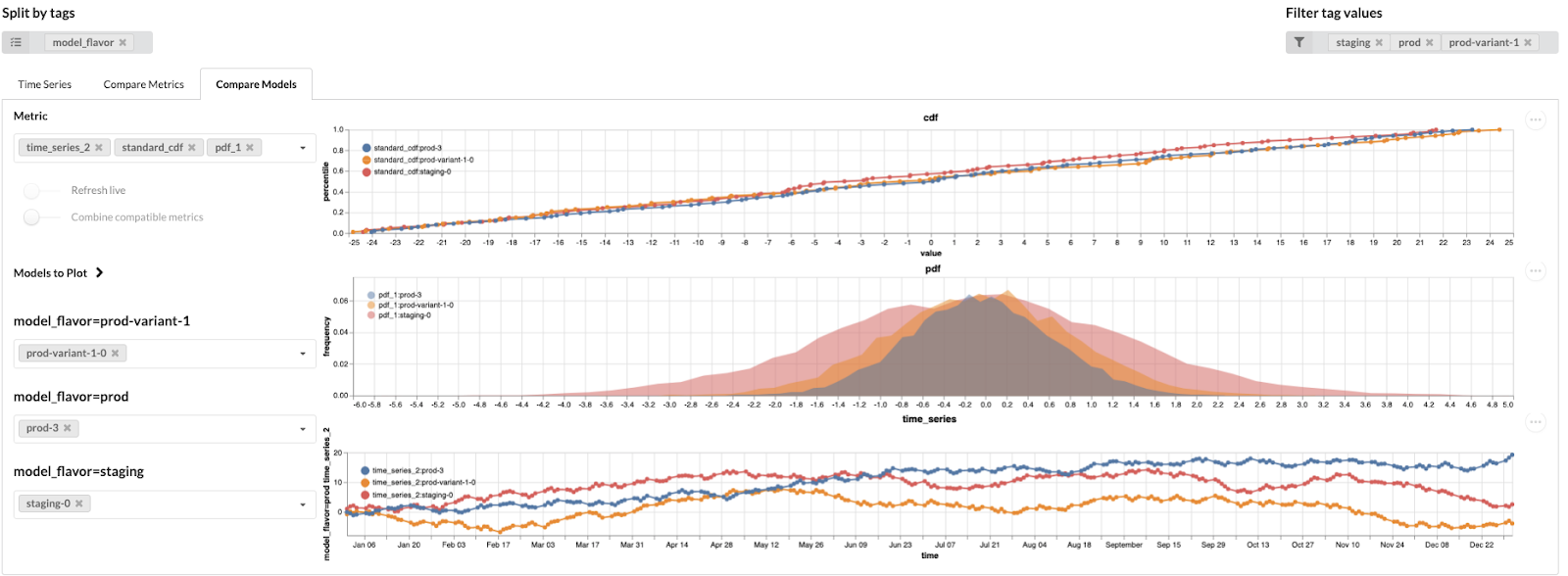
The tags add a powerful selecting capability, allowing data scientists to filter for specific values and split models into series. The types of metrics are pluggable, with a metrics structuring library we built to allow for easy specification of new metric types.
The dashboard we built, while comprehensive, does not solve every problem. That’s OK! An API and a Python client for querying metrics allows power users to retrieve metrics in bulk and analyze them in their own way.
Adoption
We’re thrilled to say that the majority of the Stitch Fix experience is powered by models built with the Model Envelope. Using the tooling laid out in aggressively helpful platform teams, we track users of the product. The platform we built powers 50+ production services, has been used by 90 unique users since the beginning of the year, and powers some components of tooling for nearly every data science team. It runs behind the scenes in every critical component of Stitch Fix’s recommendations stack, including Freestyle, the Stitch Fix home feed, and outfit generation. By providing the right high-level tooling, we’ve managed to transform the data scientist experience from thinking about microservices, batch jobs, and notebooks toward thinking about models, datasets, and dashboards.
Looking Forward
We’ve been able to create a platform that requires few trade offs and allows us to have it all. It makes use of a simple, intuitive API, yet empowers our data scientists to do meaningful work. This has massively benefited the business, allowing us to serve our customers in unique and innovative ways. That said, we still have a ways to go. In particular, we’ve already built the following related products:
- Configuration-driven training pipelines (blog post to come!)
- Framework-specific plugins for training
And are thinking through some exciting new possibilities:
- Ways to optimize certain common tasks (e.g., productionalizing PyTorch models)
- Ways to integrate feature fetching seamlessly with our models
- Monitoring for model drift between training and production
- Live monitoring of model performance
We are also considering open-sourcing components of the platform, although that could take some time. In the meanwhile, if you’re interested in getting involved with the work the ML platform team does, check out hamilton, Stitch Fix’s open-source framework for building scalable dataflows.
Developing our ML platform has been a transformative process that involves building trust with data scientists and digging deep to understand their approaches. Doing so successfully is a challenging journey, but when we succeed, we greatly improve the data scientist and client experience.