Introduction
The foundation of our recommendation stack is a scoring model we call p(sale), which estimates the probability that any given client will purchase any given item. This model has gone through many iterations over the years, from a mixed effects model, to a matrix factorization model, and now to a novel sequence-based model. Internally we call this the Client Time Series Model (aka CTSM) because of its focus on the time-domain of client interactions. This post details our new model, which is a significant improvement for both the quality of our recommendations and the maintainability of our systems.
Motivation
Before setting out to develop our new model, it was clear that the evolution of our business necessitated a change to our modeling approach. First, the growing variety of recommendations we serve led to an explosion in the number of models we needed to maintain. Each time the business expanded, such as adding Mens, or serving the UK, or adding direct shopping with Freestyle, we responded by forking a new model to serve the new channel. This was necessary because a single domain-agnostic model could not serve the new channels as well as tailored models, but over time it has increased our maintenance burden and cost of iteration.
In addition to the system complexity, we also knew we had an opportunity to make better use of important signals. With data and models separated by business line, region, and channel, we had a limited ability to leverage learning across these boundaries. With a unified model, we can more seamlessly use data from US clients to improve recommendations for UK clients, or data from Fixes to improve recommendations in Freestyle.
Finally, our previous approaches modeled clients via tabular data. Although they are trained on purchase events that take place in the context of a particular point in time, they did not explicitly consider the time dimension in their understanding of the client’s interactions. We believed that there was significant opportunity to better capture client state by making use of the time dimension in our model architecture.
Client Time Series Model
Unified Client and Item Embeddings
The Client Embedding
The core of our model is our representation of the client. To simplify the task of integrating many different data sources with many different prediction domains, we employ the simplifying abstraction of a single unified client embedding. Rather than modeling the client separately for each prediction domain, we learn a single client hidden state, with separate mappings to the separate domains.
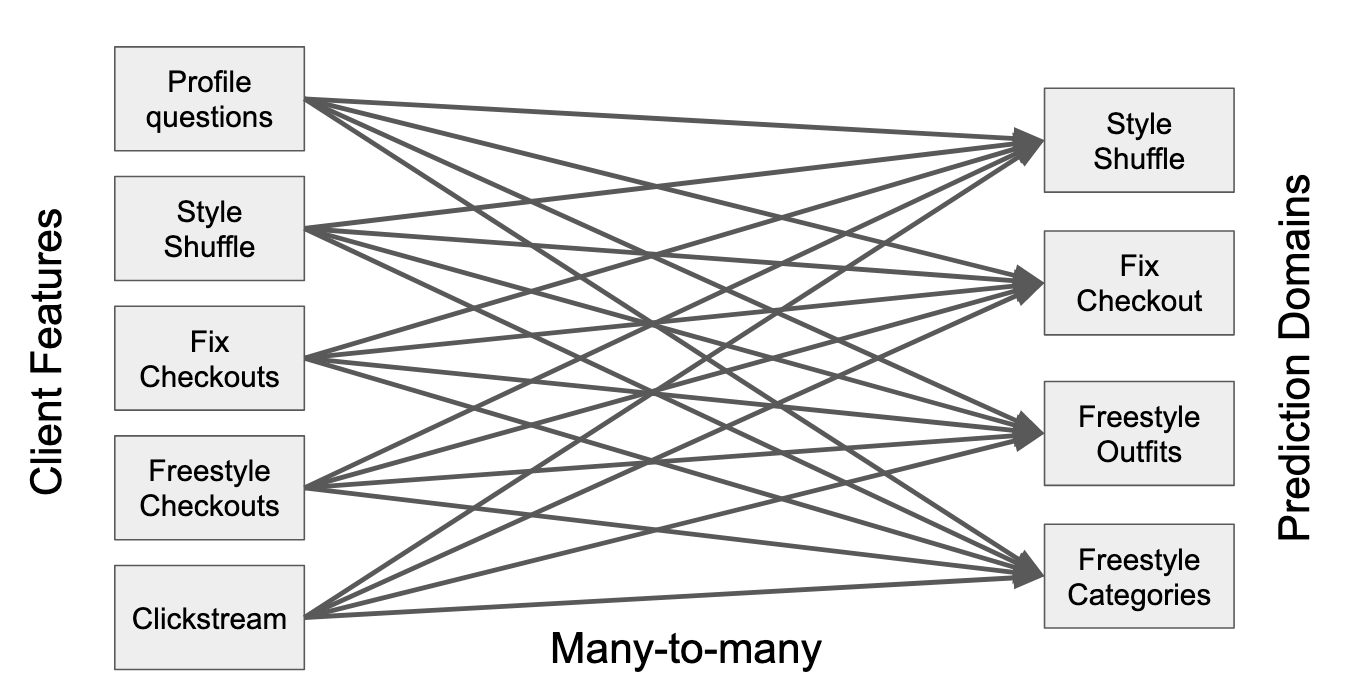
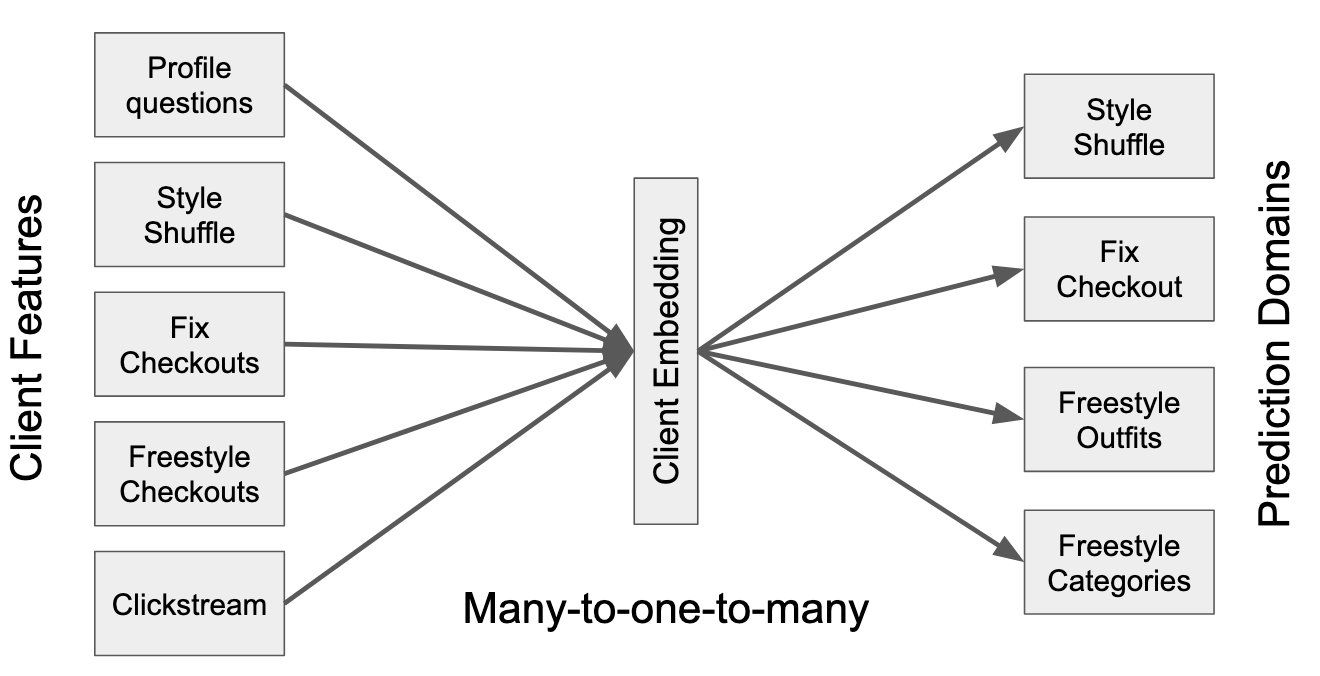
Importantly, this client embedding is not static, but rather updates with each new interaction we observe from the client. During training, predictions are made using the client embedding as of the timestamp of the predicted event. Similarly for features, every client interaction is considered a timestamped event. For example, we do not consider a client’s “waist size” to be a static feature. Rather, we consider the event when the client entered their waist size. After all, the client state and preferences are not static, but may evolve over time: in our example, at one moment in time the client’s waist size might have been 42, but at another moment in time it might change to 41. Using the most recent value of 41 as a feature for interactions that happened at the time it was still 42 would be incorrect. Another example of an event is an interaction with an item: at one moment in time a client might like a certain style of shoes, but as style preferences evolve, the client might prefer a different style of shoes at another moment in time. Both cases demonstrate that a client state evolves over time, and CTSM captures these dynamics.
A consequence is that it is time-safe by design: by considering events chronologically, we avoid the pitfall that past observations are informed by future events, which can easily be a problem when using tabular machine learning models.
The Item Embedding
We use an EmbeddingBag approach to construct embeddings of our items by summing up the embeddings we learn for item features. This is a fairly standard approach, similar to the original matrix factorization approach in the original Netflix Prize paper1. While we model clients with a single client hidden state that we then transform into embeddings for each prediction context, we use the same item embedding in all contexts. Some backtesting has shown we may not benefit from similar additional transformations to have separate item embeddings for each context.
Temporally-Masked Encoder with Gated Updates
A key component of CTSM is the Temporally-Masked Encoder (TME) with gated updates. The TME is similar to a transformer3, but is faster and easier to train. Moreover, in our backtesting results TME performed better than a traditional transformer. The main difference is that TME computes weights only once for the whole sequence rather than separately for each input as a function of queries and keys. See Figure 3 for an overview of TME.
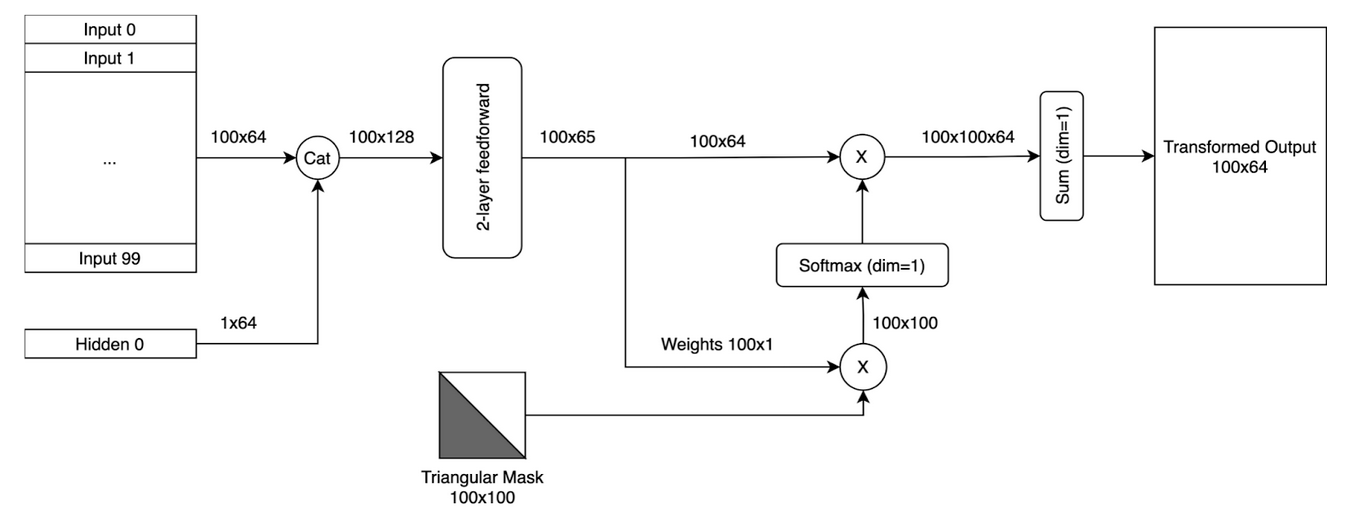
In the example in Figure 3, the embedding dimension is equal to 64. The MaskedEncoder takes a batch of updates (100 in this case), along with the current client hidden state, and passes their concatenation through a 2-layer feedforward network that yields 100 processed updates along with a single vector of weights. The weights are combined with a triangular mask in order to perform a backwards looking weighted sum. Because the updates have been ordered by time, the MaskedEncoder encodes each update as a timesafe weighted average of itself and the previous updates in the same batch, all mixed with the current client hidden state.
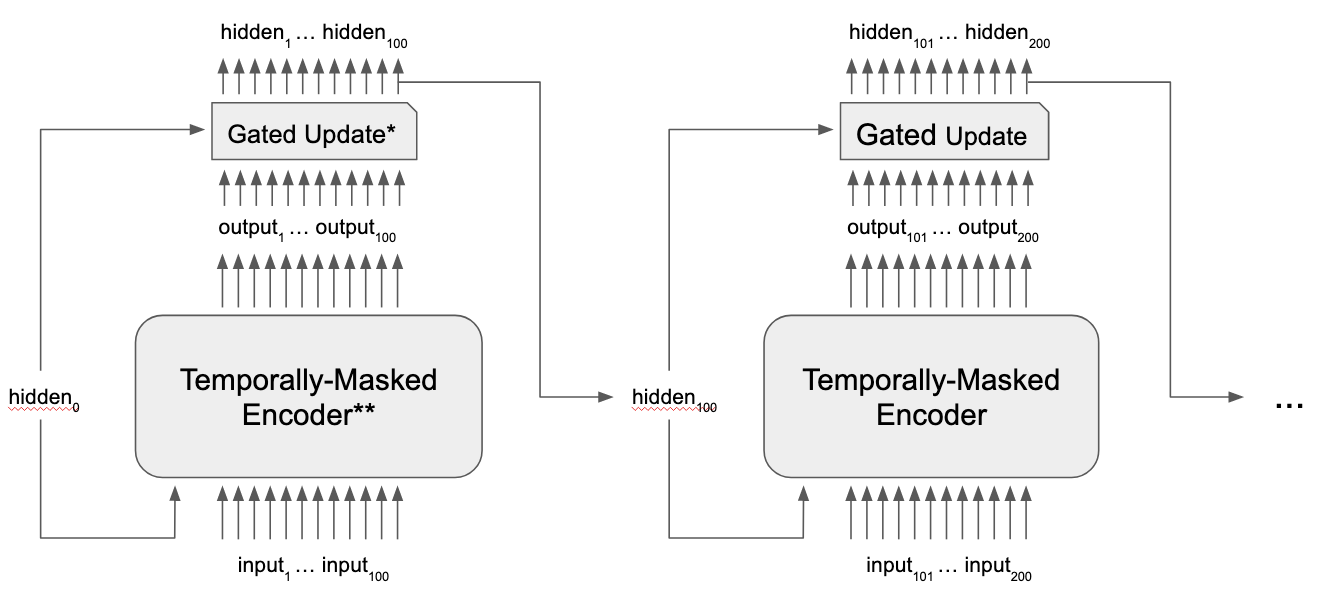
We break down training into subsequences of updates, storing the client hidden state and passing it along from one subsequence to the next. Updates are encoded with the MaskedEncoder, and then client hidden states are updated by passing the existing client hidden state through a GRU-style gate2 along with an encoded update. In this way, we have some of the sequentiality of an RNN (through the GRU updating of the client hidden state) and some of the benefits of the parallelization of transformers (all updates within a subsequence are processed in parallel) See Figure 4 for an overview.
Instant reflection of updates to rankings
A key aspect to improve the client experience is to reflect any client’s interaction with the platforms instantly in the recommended items. For example, if a client updates their profile, the recommendations on Freestyle should immediately reflect this. If a client plays Style Shuffle and subsequently orders a Fix, we want the items that are surfaced to the stylist to immediately reflect the client’s likes and dislikes. In short, any update on the client profile or client interactions should be instantly reflected in all platforms. CTSM is able to efficiently deal with updates across platforms: At inference time, the only features that have to be passed to the model are all client events that have happened since training, since everything else is reflected in the client embeddings already. Since CTSM doesn’t require complex feature engineering or similar, the raw (or almost raw) features can instantly be directed to CTSM as client event updates such that any recommendations reflect those recent events.
Modeling events
There are two main flavors of events: Updates and Targets.
Updates
Updates are observations of some piece of information that changes our knowledge about the client state. For example, a Fix checkout or a profile change is considered an update. Updates have four components: source, timestamp, client identifier, and payload. The source identifies what type of update we are dealing with. The timestamp identifies when the event took place. The client identifier points to the client to which the update refers. The payload contains any features or information and may differ per source. However, all updates from the same context have the same payload structure. For example, the payload for a Fix checkout might contain an item embedding and an outcome, signifying whether the client purchased the item or not. Each update is then transformed into a fixed dimensional embedding, which is used as an input to the TME. See Figure 5 for an illustration of this process.
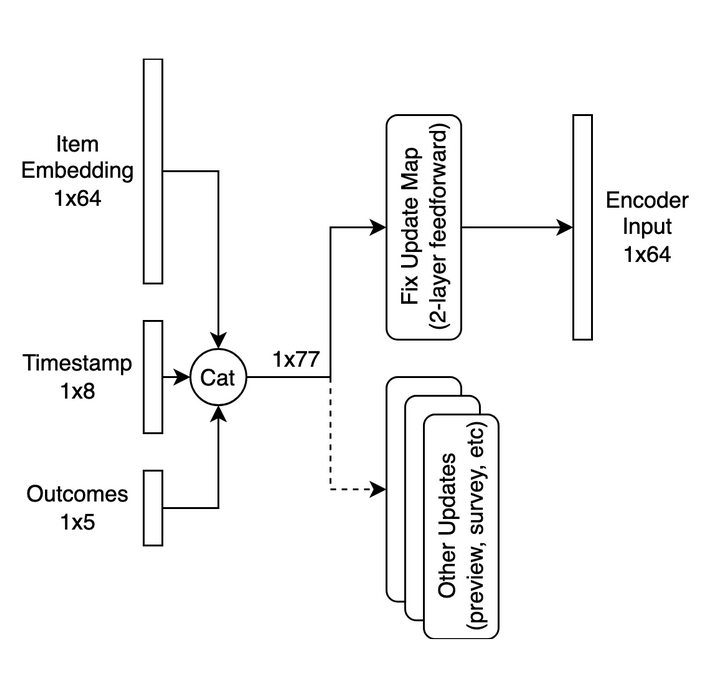
Targets
Targets are outcomes of interest to estimate as a function of the client state. An example of a target is the probability that a client purchases an item conditional to the item being sent to the client in a Fix. Each target has an associated loss function, such as binary cross entropy. Targets may correspond to updates, but this is not required. For example, a Fix purchase may be included as an Update as well as a Target. Targets contain the same components as updates, namely source, timestamp, client identifier, and payload, but additionally requires an associated loss function that measures predictions against outcomes from the payload. In our fix checkout example from the updates, the loss function is measured against the ‘outcome’ inside the payload.
To make a target prediction, the most recent client embedding prior to the target timestamp is fetched, as well as the item embedding. The client vector is then transformed to the item embedding space using a 2-layer feed-forward neural network. The dot product of the two gives us the predicted logits, which can be transformed into the predicted probability by applying the expit function. See Figure 6 for an illustration of this process.
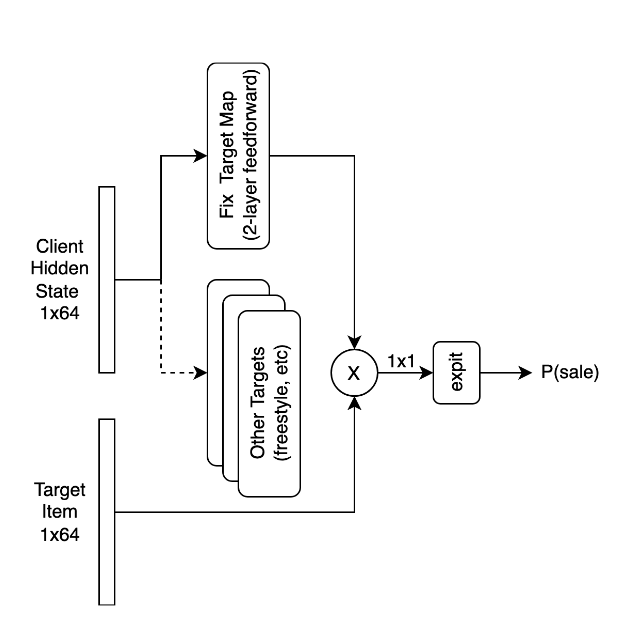
Concluding Remarks
The productionized version of CTSM has been a great success for Stitch Fix. Before rolling out the model to all our business lines, regions, and experiences, we performed A/B tests of CTSM against the predecessor models across our Womens, Mens, and Kids business lines, across our US and the UK regions, and across our Fix and Freestyle channels. We found benefits in four main categories:
- Key Performance Indices. We saw an improvement on virtually all our KPIs, such as revenue, retention, and client satisfaction.
- Computing resources. We saw a tremendous reduction in resource consumption. First of all, we now only train one machine learning model, whereas before we trained several machine learning models, by region, business line, and shopping experience. Second, the inference endpoint consumes less resources than the combined resources needed for all predecessor models.
- Lower maintenance. CTSM requires less maintenance than our predecessor models, because now we only have to maintain one repository, training pipeline and endpoint, while previously we had to maintain several. Also, due to the nature of CTSM we do not have to maintain complex preprocessing jobs or engineered features. We only have to input the raw features with minimal preprocessing.
- Accelerated development. The benefits above aid us exponentially: the reduced maintenance frees up time on the team to focus on developing and improving our model and endpoint, and the unified framework has greatly accelerated our development velocity. For example, we recently developed an improved subsampling technique for the Freestyle target logic. Because CTSM handles each target as a modular component, we could do this easily and quickly in one place without touching other event sources like Fix targets or survey updates.
To conclude, we are now better than ever connecting our clients with the items they love, using a more stable and computationally efficient system, and we believe that we can continue to deliver improvements in our recommendations at an accelerated pace.
References
[1] Yehuda Koren, Robert Bell, and Chris Volinsky. 2009. Matrix factorization techniques for recommender systems. Computer 42, no. 8 (2009): 30-37.
[2] Kyunghyun Cho, Bart van Merriënboer, Dzmitry Bahdanau, and Yoshua Bengio. 2014. On the Properties of Neural Machine Translation: Encoder–Decoder Approaches. In Proceedings of SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation. 103–111.
[3] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems 30 (2017).