At Stitch Fix, data scientists have great autonomy to iterate on and improve our customer’s experience. They do this by regularly training, retraining, and deploying a diverse fleet of machine learning models that each play a vital role in Stitch Fix’s business. As a core component of the algorithms platform, the Model Lifecycle team is responsible for enabling data science teams to scale, by streamlining the process of getting these models into production. In our last post, we discussed the tooling we built that enables Data Scientists to deploy and monitor models with the push of a button. In this post, we’re going to dive into how we improved the model training experience.
Motivation
As we researched how data scientists built their models at Stitch Fix, a typical pattern emerged. We observed three distinct phases of model development:
- Ideation: The data scientist models a problem and iterates on potential solutions.
- Workflow development: The data scientist compiles the chosen solution into a production-ready framework. They:
- Write modules that handle training, data loading, and training orchestration
- Write a DAG in our abstraction on top of airflow to call these modules from within tasks and send data between them
- Publish this workflow to production
- Workflow iteration: Issues regularly occur in production pipelines. To debug and fix, the data scientist will try to:
- Execute the workflow in staging
- Diagnose task failures from run logs
- Fix and republish the workflow
- Execute the workflow to demonstrate that the fix works by examining the production state
While analyzing these workflows, we found that the standard approach was lacking the following best practices:
- Configurability: Nothing in the above workflow guarantees that the code is configurable for further iteration.
- Separation of concerns: All the code (orchestration, infrastructure, data) in this approach is bundled together, making surgical changes messy and complicated.
- DRY code: The logic to orchestrate training, building, and publishing workflows is repetitive in nature – a lot of it can be factored out.
- Easy migrations: Good luck migrating an entirely custom codebase without any of the above properties!
The system we built alleviates the concerns above, by providing a common framework for data scientists at Stitch Fix to develop and execute training pipelines.
Design goals
Keeping the above criterion in mind, we came up with the following design goals:
- Higher-level abstractions: When the data scientist is ideating, they should be able to build their workflow out of simple high-level abstractions such as datasets, trainers and models.
- Faster iteration: Developing models should be fast.
- Principled code organization: The code should be organized with a separation of concerns in mind. For example, the code to train a model and the code to run inference over a dataset should be stored separately (but be easy to reference).
- Operational simplicity: When underlying infrastructure or dependencies change, the data scientist should be able to migrate with little to no effort.
- Unified environments: A data scientist should be able to use the same code in production as they do when developing a model.
Designing for Stitch Fix
Using our framework, data scientists at Stitch Fix have access to two high-level building blocks:
- Extracts: For generating features a model needs to train
- Trainer: For building the final trained model
To train their models, data scientists need to simply implement the interfaces above and glue them together with some configuration files (details to come shortly). The framework we built takes care of the rest – orchestration, workflow compilation, and managing compute/scalability.
A regression example
To illustrate how the framework works, let’s walk through an example of a fairly simple workflow – training a linear regression model using sklearn. All these configurations reside in .yaml files within a GitHub repository managed by the data scientist.
Extract configuration
Here we specify an extract by executing a SQL script, located in a file templated with jinja.
The framework executes the query and stores the data in our internal data warehouse.
This is one of a variety of methods the framework provides to specify an extract.
We name the below file extract_inputs.yaml:
# to reference what this represents in another configuration,
# we need to point to this file and specify `training_data`.
training_data:
operator: sql
sql_file: training_data.sql
kwargs:
limit: 10000 # A parameter that gets injected into the .sql file
Model configuration
Here, SKLearnLinearRegressionTrainer is the trainer module that we want to orchestrate. The contructor_args
for the trainer accept feature column names and hyperparameters (such as fit_intercept) which are required for training the model.
Finally, the dependencies section specifies the mapping between the extracted data and the trainer’s train method.
# required -- these end up as indexes in model envelope
model_name: A regression model
model_description: This is a sample linear regression model.
tags: # for integrating with model envelope indexing (see prior post)
canonical_name: sample_regression_model_v1
# model trainer to use
model_trainer: sklearn.sklearn_linear.SKLearnLinearRegressionTrainer
constructor_args:
fit_intercept: False
feature_columns:
- x_0
- x_1
- x_2
target_label: y
# things that we want to happen before this model is trained
dependencies:
data:
- train_param_name: df # maps to the parameter in train()
file: extract_inputs.yaml # points to extract defined above
file_param_name: training_data # the variable within the extract file
The trainer
The trainer implements the AbstractTrainer interface. The train method returns an object that encapsulates a model as a pure function, as well as
other lifecycle methods such as evaluate, which enables computation of metrics on the trained model.
The beauty of using configurations here is that you can introduce new datasets and modify training hyperparameters without touching the trainer code.
@dataclass
class SKLearnLinearRegressionTrainer(
AbstractTrainer[SKLearnLinearRegressionModel]
):
# Note that these constructor parameters correspond to those passed in the file above
fit_intercept: bool
feature_columns: List[str]
target_label: str = "target"
def train(self, df: pd.DataFrame) -> TrainedObject:
# df maps to train_param_name in model configuration
regression_model = linear_model.LinearRegression(
fit_intercept=self.fit_intercept,
normalize=self.normalize,
n_jobs=self.n_jobs,
)
features = df[self.feature_columns]
regression_model.fit(features, df[self.target_label])
# the wrapper model containing the state
model = SKLearnLinearRegressionModel(
model=regression_model,
feature_columns=self.feature_columns,
target_label=self.target_label,
)
# return the wrapper model that will be stored to the model store
return TrainedObject(
model,
# We use the following parameters to derive the model's signature
sample_input_data={"x": features},
sample_output_data=model.predict(features),
method="predict",
)
def evaluate(
self,
model: SKLearnLinearRegressionModel,
df: pd.DataFrame,
# Evaluate is passed the trained model from the previous step
) -> Dict[str, Any]:
df_predicted = model.predict(df[self.feature_columns])
mean_squared_error = metrics.mean_squared_error(
df[self.target_label], df_predicted
)
return {'mean_squared_error' : mean_squared_error}
The model
The model is a simple wrapper over a model’s functionality. It is the only component that gets saved to the model store.
@dataclass
class SKLearnLinearRegressionModel:
model: linear_model.LinearRegression
feature_columns: typing.List[str]
target_label: str = "target"
def predict(self, x: pd.DataFrame) -> pd.DataFrame:
predicted = self.model.predict(x)
return pd.DataFrame(predicted, columns=[self.target_label])
Iterating locally
The pipelines can be iterated on locally using a dash application that launches and renders the execution graph. The datasets are cached to allow for sampling and exploration. Changes to the trainer’s implementation can be made on the fly and tested by stepping through trainer execution.

Behind the scenes
We transform the YAML files the user provides into an intermediate representation as a directed acyclic graph, which we then compile
to Stitch Fix’s internal airflow-based orchestration system.
This provides an additional layer of abstraction, while enabling us to leverage the
awesome set of operators that other platform teams build.
The intermediate layer of abstraction gives us the ability to do the following without a data scientist’s involvement.
- Migrate seamlessly: Since we control the translation layer, we can make necessary changes to the underlying infrastructure. A simple republish will migrate the code base for the data scientist.
- Switch backends: If we find a better orchestration solution than airflow, we can easily switch to it.
- Swap orchestration strategies: Since data scientists conform to the trainer interface and we control orchestration, we can implement a variety of orchestration strategies for training (see below).
The goodies
With the trainer and extract abstractions, we can enable different orchestration strategies without touching the trainer code.
We provide the following orchestration strategies out of the box:
- Tuning: By adding a configuration with the parameter space to explore, the framework will conduct a search through hyperparameter space to tune the model.
We support
Guassian ProcessandGrid Searchtuning strategies.model: model_linear_regression.yaml environment: memory: 2000 cpu: 2000 n_function_compute_workers: 4 tuning_type: grid param_boundaries: alpha: - 0.1 - 0.8 - 0.1 #step size only valid for tuning_type grid max_iter: - 10 - 50 - 10 #step size only valid for tuning_type grid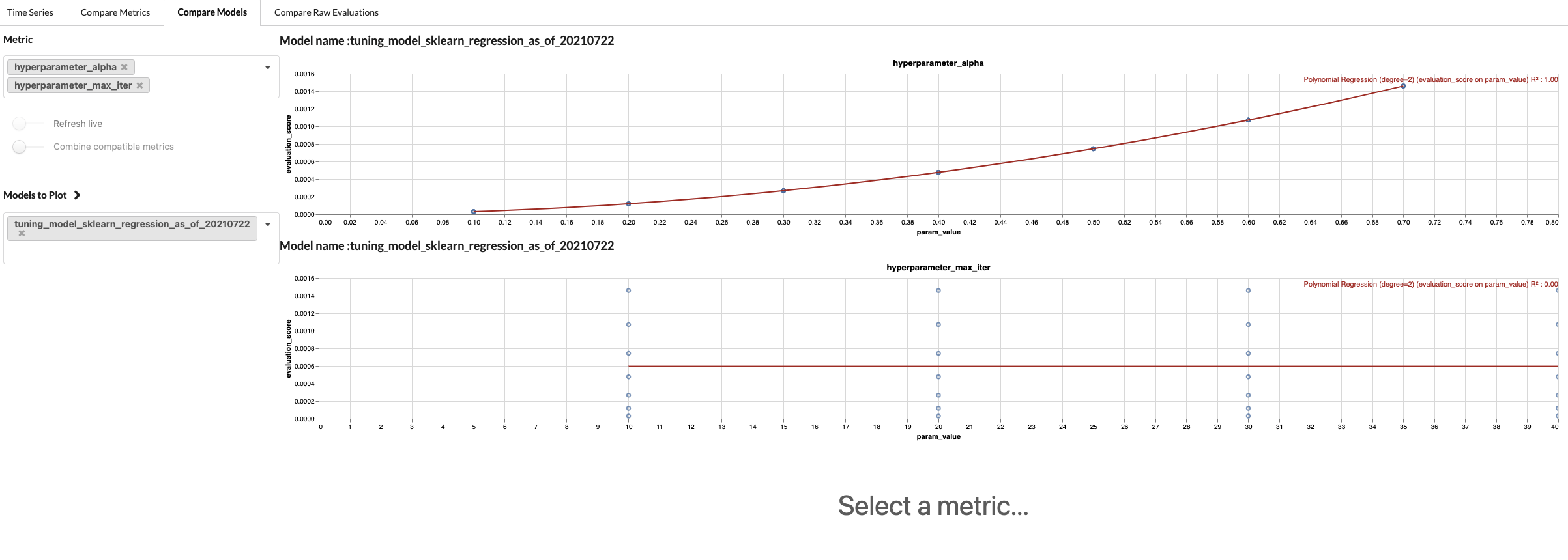
The effect of changing hyperparameters on the loss value of a model. max_iter has no impact on model performance, whereas alpha is correlated. - Backtesting: By choosing a data splitting strategy, a user can see how their model performs on unseen data.
In the snippet below in the model.yaml file:- You pick the strategy as sliding_time_window .
- days_backward represents the length of data to look at.
- The data splits will slide over the window above by 2 days.
- train_size represents the size of each training window.
- test_size represents the size of testing window.
split_config: train_param_name: df strategy: sliding_time_window days_backward: 60 train_size: days: 10 test_size: days: 5 slide_by: days: 2Training models at various time periods allows you to measure how accurate your model is at different points of time. And one can examine the performance of these strategies on a per metric basis.
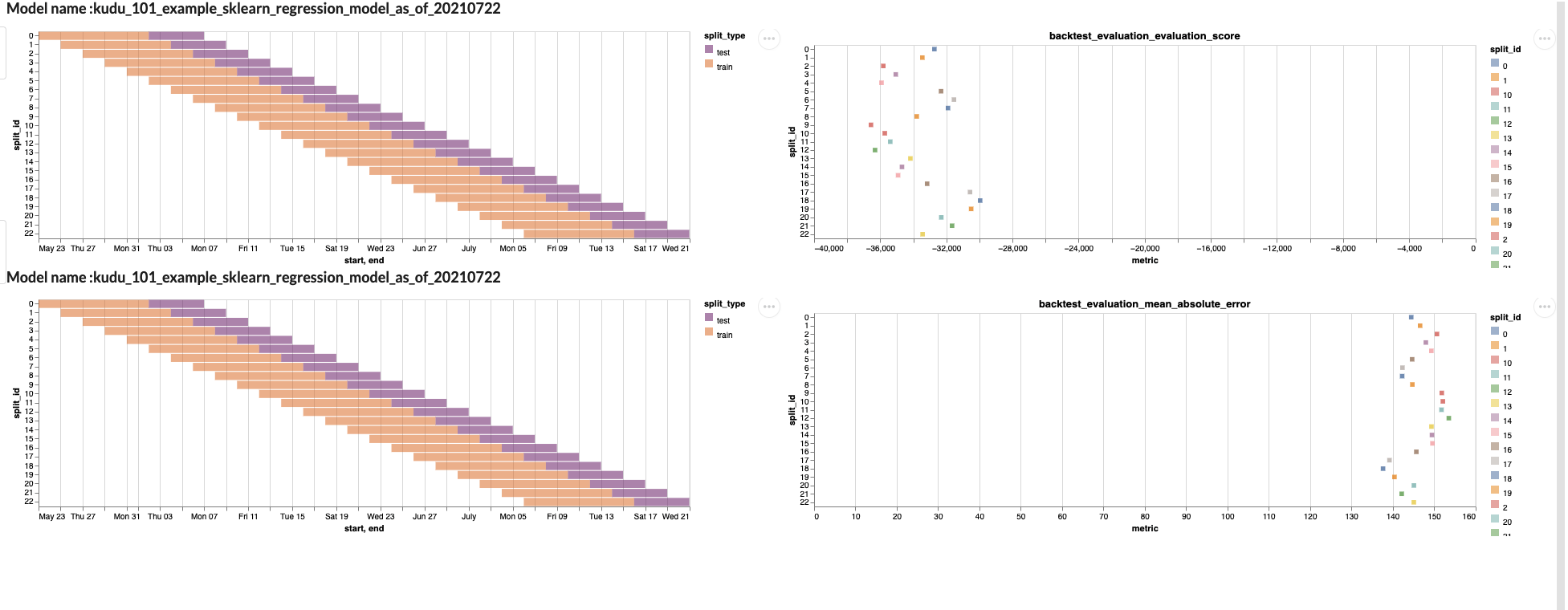
Window size for training/testing (left) juxtaposed with corresponding evaluation metrics (right)
Looking onward
We’ve made a lot of progress, but still have a ways to go. We’re currently working on:
- Model and dataset observability: Dataset and model performance monitoring, both at training and at inference time
- Pytorch lightning support: Auto-logging of metrics along with custom PyTorch data loaders
Adoption
With configuration-driven pipelines, we have unencumbered the data scientists by enabling them to focus on doing what they do best; training models. The reception within Stitch Fix tells the story for itself – we have over 68 workflows running using our system. These were created by 30 data scientists and regularly train and retrain 200+ distinct production models, including those powering Stitch Fix’s core recommendation stack.
Some parting thoughts
As the machine learning platform team, we measure success in our ability to boost data scientist productivity. By building higher-level abstractions that reduce the cognitive surface area for data scientists, we have managed to improve the onboarding experience while simultaneously empowering platform teams to run a tighter ship on deployed models.
We discussed our training framework here – this is but one of the tools that streamline model development. We have also written about:
- Hamilton (open source!): For managing dataflows
- Model Envelope: For getting the models we train into production
These tools would be impossible without the incredible set of platform tooling Stitch fix has already built – we would be remiss if we did not acknowledge the giants, on whose shoulders we stand. For more details, check out articles on our home-built experimentation platform, data warehouse, and kafka tooling.