Introduction
At Stitch Fix, our data platform is designed to be self-service, with our users taking ownership of their own ETL, models, and microservices. To support this approach, the platform team prioritizes user autonomy and end-to-end tooling in their tooling designs, minimizing the involvement of platform engineers in day-to-day engineering and data science workflows.
We regularly evaluate our infrastructure against new frameworks to assess the costs and benefits of potential updates. Last year, we transitioned our EMR-based Spark infrastructure to EKS to take advantage of its benefits. The next logical step was to re-examine how our core platform services were deployed and updated, especially those still deployed directly to instances.
We also recognized that Kubernetes, a popular open-source system for handling the deployment of containerized applications, could provide benefits for microservice orchestration beyond just batch compute infrastructure. Our existing instance-based service deployment framework was beginning to show its age in areas that were critical for Stitch Fix, such as the development lifecycle’s velocity. As we saw an opportunity to leverage Kubernetes to address these issues, we identified pain points in our service deployment ecosystem.
Pain Points
-
Building and deploying services can be a time-consuming process, involving multiple steps and dependencies. We needed a solution that would streamline this process and enable us to deploy services more efficiently.
-
Polyglot environments, where multiple programming languages are used within the same system, can present a challenge for deployment standardization. At Stitch Fix, we use a variety of languages, including Python, Golang, Nodejs, and JVM (Java and Scala), making it difficult to establish consistent deployment practices across the board. We needed a way to deploy polyglot environments in a standardized and efficient manner.
-
Autoscaling and rollback capabilities are essential for managing service deployment at scale. At Stitch Fix, we found that our existing infrastructure had limited capabilities in these areas. We needed a solution that would enable us to easily scale services up and down as needed, and quickly rollback changes if necessary.
-
Traffic segmentation is an important aspect of service deployment, enabling us to direct traffic to different parts of our infrastructure based on various factors. However, we found that we were using different solutions for traffic segmentation across our various services, which created inconsistencies and added complexity to our infrastructure. We needed a solution that would enable us to manage traffic segmentation in a consistent and efficient manner.
We evaluated industry options and were pleased to realize that we could address our pain points by adopting open source tools and applying a dash of Stitch Fix flavor. And, so we did: introducing the Service Operator Service (SOS)!
Introducing: Service Operator Service (SOS)
The Philosophy
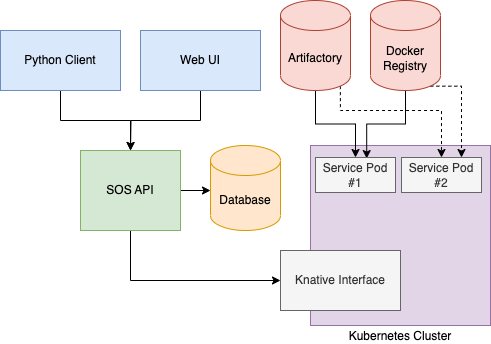
SOS is a service deployment framework based on Kubernetes, designed to enable Stitch Fix data platform engineers, data engineers, and data scientists to manage their own deployment lifecycle through a self-service approach.
With SOS, end users can interact with a streamlined set of tools, without the need to learn or be aware of Kubernetes. Meanwhile, maintainers can remain agile with industry-standard tools by leveraging cloud-native open-source software such as Knative and building on top of a thin layer of opinionated APIs. Knative offers a simplified abstraction that streamlines certain aspects of the Kubernetes application deployment process, including the management of network configurations.
Addressing the Pain Points
The design of SOS focused on a set of key features centered around addressing our previously-detailed pain points:
Fast Deployments
Deployments in SOS are lightning-fast, thanks to two design decisions: we use Knative to reduce overhead, and we run all services as artifacts on standardized Docker images.
Knative’s quick pod provisioning is a major advantage, as we’ve discovered firsthand - our deployments can be up and running in under 10 seconds. One of the ways Knative achieves this is by using a shared load balancer for all deployments, which reduces the overhead of deploying a new service.
In SOS, each revision of a service is a self-contained artifact that runs on a curated Docker image specific to the service’s language - Python, NodeJS, Golang, or JVM. This approach, while standard for Golang binaries and JVM jars, can be more challenging with Python due to its less-robust dependency management and portability issues.
With this in mind, we set up a remote build process for each supported language that can compile an artifact on the same Docker image that the artifact would be run on. Each of the languages artifacts are defined as follows:
- Golang - Golang binary
- JVM - executable assembly jar file
- Python - shiv archive creates self-contained Python zipapps
- NodeJS - ncc compiles a NodeJS project into a single file
By bundling all dependencies within the artifact, we save significant time - anywhere from a few seconds to several minutes - that would otherwise be spent installing dependencies during runtime. As a result, services can enter a ready state more quickly. For services that have a more complex set of Python dependencies, we’ve seen time savings of more than 5 minutes!
Standardized Build and Deployment Processes
Build Process
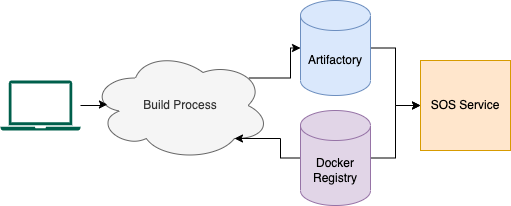
In addition to infrastructure work, we realized that for SOS to succeed, it was essential to offer a streamlined and straightforward method for users to create their artifacts. Without a standardized build and deploy process, users would have to sift through documentation to set up their local environments and handle processor architectures. We wanted to alleviate these overheads and provide users a least-resistance path to start experiencing SOS – batteries are included!
To address this issue, we established a command-line tool where running sos build in your project directory will automatically detect project metadata (such as if it’s a Python or Golang deployment), perform integrity checks, and launch a remote build job that creates the SOS artifact on the same Docker image it would run on.
Deploy Process
We offer two interfaces for creating and updating service deployments in SOS: a Python client and a web-based UI built with React.
The Python client allows users to declare their services as a DSL in a familiar Python ecosystem. To ensure consistent types, we synchronize data models between the SOS client and the SOS API using shared protobuf files. We will cover the Python client’s user interface in more detail later.
Our web-based UI allows users to easily review revision histories and adjust traffic policies. We have ensured feature parity between the Python client and the web UI, enabling our users to choose the interface that suits them best.
Traffic Segmentation and Responsive Autoscaling Over Multiple Axes
SOS included traffic segmentation and responsive scaling as a key feature for several reasons. These features enabled faster deployments and rollbacks, which facilitated shorter development cycles. Moreover, because all metrics and logs are namespaced by the traffic segmentation, we gained much better insights into service behavior. This feature also made gradual traffic cutovers possible and allowed for fast autoscaling to handle traffic bursts while reducing costs by scaling down unused instances.
For example, by setting services to use a minimum of zero instances, it is possible to make SOS services serverless. No pods would be provisioned until they receive traffic. Implementing this feature for our services allowed us to save significant costs on staging deployments and production services that receive less constant traffic.
The SOS User Experience
Blissful Ignorance
Users don’t need to be aware that SOS runs on Kubernetes - all they need to do to start deploying services is install the SOS Python client!
Decoupled Application and System
SOS ensures that each user’s new code deployment is immutable and has a unique ID, tied to an SOS artifact with its own dependencies. This decouples the system and application, setting clear boundaries and avoiding the issue of Nginx configs and secrets management bundled into an application’s source code that we faced with our previous instance-based deployment.
We wanted to avoid a scenario where users inherit and patch and layers of Docker images until they become unmaintainable black boxes. By running all service artifacts on top of curated Docker images, we avoided the problem of users managing their own Docker images. This made it easier to implement platform-wide changes over time, as we could patch and improve the Docker images without relying on users to rebuild their applications. This also allowed us to efficiently tweak and fine-tune the observability agents on the system.
Single Source of Truth
The SOS service itself is the source of truth for each deployment, so users don’t need to manage multiple configurations for the same service. When deploying a service, the SOS service will merge any necessary files at the service level, which prevents confusion that can arise when configuration files are stored in different branches or exist only in a user’s local environment.
The Experience
The SOS Python client is the tool that our users use to interact with SOS. Below are some examples of the SOS Python client and how a user would use it to define their service deployment.
Service Creation
Each SOS service correlates with a service that’s created in Kubernetes.
service = Service(
id="sfix_service",
owner_id=":team:sfix_team_name",
env="prod",
)
Creating a Revision
In SOS, a service can have multiple revisions, with each revision representing an immutable version of the service that can be deployed independently.
The example below shows the minimal configurations to create a revision that deploys a Python artifact. The Artifact is a self-contained Python artifact that has been deployed to Artifactory, which we use as our sink of artifacts.
revision = Revision(
id="sfix_service-5",
artifact=Artifact(name="sfix_service", version="v0.0.16"),
python_config=PythonConfig(
python_version="3.9",
gunicorn_config=GunicornConfig(worker_class="gevent"),
app_module="sfix_service.server:app",
),
)
logging.info(service.add_revision(revision))
Additional settings can be configured for more complex deployments, such as port number, environment variables, memory and CPU allocation, health checks, and thread and worker counts. Here’s an example of how to set these configurations:
revision = Revision(
id="sfix_service-5",
artifact=Artifact(name="sfix_service", version="v0.0.16"),
container=Container(
port=5001,
env_vars=[EnvVar(id="env_var", value="env_value")],
resources=Resources(memory="2G", cpu="1000m"),
),
health_check=HealthCheck(liveness_probe="/", readiness_probe="/"),
sf_env="prod",
python_config=PythonConfig(
python_version="3.9",
gunicorn_config=GunicornConfig(worker_count=4, thread_count=8, worker_class="gevent"),
app_module="sfix_service.server:app",
),
autoscaling=Autoscaling(min_scale=6),
)
logging.info(service.add_revision(revision))
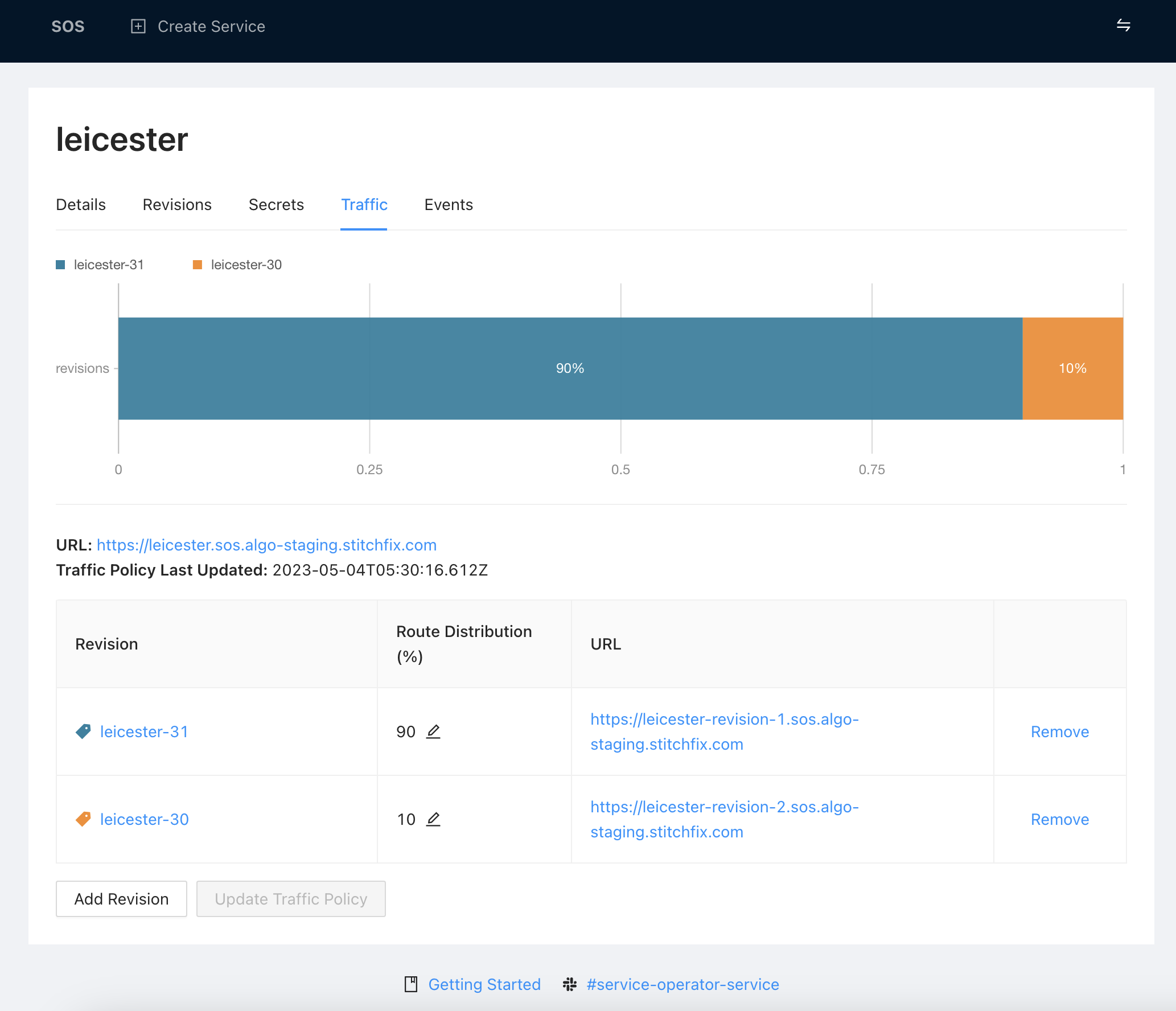
Set Traffic for New Revision
We recognized the importance of providing robust support for traffic segmentation, as users should have confidence that deploying new code wouldn’t negatively impact their entire system. By giving them complete control over the flow of traffic, they could confidently iterate on changes without fear of breaking everything. This was crucial to enabling faster development cycles and smoother rollbacks, as well as improving our understanding of service behavior through fine-grained traffic analysis.
The following example shows how the newly created revision can be set to receive 100% traffic. However, to roll out changes more safely, traffic can be segmented between multiple revisions by adding more Route objects to the TrafficRoute.routes configuration. SOS’s observability tooling can be used to monitor the traffic and ensure a smooth transition.
service.add_traffic(
Traffic(
traffic_route=TrafficRoute(
routes=[
Route(
percent=100,
revision_id="sfix_service-5",
dns_record_suffix="active",
),
]
),
)
)
The Present and the Future
Most data platform services have already been migrated to SOS. It hosts many critical services, including the components of our batch processor, job execution engine, our metastore, configuration management service, Kafka connect cluster, ownership discovery service, and more! While there are some data science services deployed on SOS, most of the currently-deployed services are focused on powering our data platform.
SOS aims to streamline the service lifecycle, yet its opinionated approach might not suit all deployments. Certain open-source tools align better with standard industry patterns. For instance, we deploy Trino directly onto Kubernetes and use a Helm Chart for Airflow. While SOS isn’t a one-size-fits-all solution, it remains highly effective for the majority of our existing and future deployments.
We are regularly improving the user experience of SOS by migrating existing services and building new ones on top of it. Our goal is to reduce the complexity of service deployment and continue to empower our data scientists and engineers at Stitch Fix to be more efficient and effective.