
Towards Service Deployment Agility
Our journey building our service deployment system and tools by leveraging Kubernetes and Knative
Our journey building our service deployment system and tools by leveraging Kubernetes and Knative
Navigating and troubleshooting complex ML and engineering systems, especially those with numerous components, can often be an intricate and challenging task. To address this at Stitch Fix, we have developed Ariadne, an innovative observability UI, in conjunction with our advanced personalized search ecosystem. In this blog post, we will delve into how observability and system design inform each other in a reciprocal relationship.
How Stitch Fix implemented distributed model training to accelerate developer velocity and ability to improve models.
How Stitch Fix uses an expert-in-the-loop approach with generative AI to drive innovation.
A sampling of the projects and areas of research done by our 2022 interns.
How Stitch Fix enables data scientists to do more, by doing less.
A Multi-Target Recommender System that is a significant improvement for both the quality of our recommendations and the maintainability of our systems
Algo Hour, Oct 11th, 2022 - Featuring Alessya Visnjic from whyLogs!
Our stylists' expertise is a differentiator for Stitch Fix. Here is how we take that expertise into account when designing algorithmic systems.
How configuration driven Machine learning pipelines help streamline the model development at Stitch Fix.
In late 2021 we released Hamilton, Stitch Fix’s open-source microframework for managing dataflows. With feedback from the community, we’ve implemented an exciting new feature -- the ability to validate the data hamilton generates! In this post we detail the new capabilities and talk a little bit about next steps.
Client feedback is at the heart of Stitch Fix. Here is how we take client's textual feedback into account.
How Stitch Fix's machine learning platform enables data scientists to scale beyond their wildest dreams.
This post describes our migration journey of Spark from EMR on EC2 to EMR on EKS.
A few months ago we released Hamilton, Stitch Fix’s open-source microframework for managing dataflows. With feedback from the community, we’ve implemented a variety of new features that make it more general purpose for Data Science/Data Engineering teams. Importantly, Hamilton now operates over any python object types, and can integrate with a variety of distributed compute platforms.
This post is a re-posting of an article first published at oreilly.com.
This post showcases what a Platform and DS team can accomplish collaborating at Stitch Fix.
Good for the business can also be good for the world. We’re proud and humbled to share our work using inventory algorithms to support entrepreneurs of color.
See who's out in the wild for the month of September.
Query based recommendations via representation learning
A brief introduction to double robust estimation
Retrospectives on a year of public talks.
Algo Hour, May 25th, 2021 - Featuring Xiaoyu Li!
See who's out in the wild for the month of June.
Building the raw materials for personalization at scale
See who's out in the wild for the month of May.
Join the Stitch Fix Algorithms team for Algo-Hour; May 25th, 2021 at 2:00PM PST, featuring Xiaoyu Li!
A contextual multi-objective multi-armed bandit framework that allows us to quantify and navigate business trade-offs.
See who's out in the wild for the month of April.
We're shifting from rapid development and iteration of our algorithms to a slower and more hand-crafted approach.
How forecasting can benefit from observable exogenous variables like the relative position of the planets and the stars.
Algo Hour, Feb 16th, 2021 - Featuring Lihua Lei!
See who's out in the wild for the month of March.
Algo Hour, Jan 26th, 2020 - Featuring Melanie Weber!
Algo Hour, Jan 26th, 2020 - Featuring Art Owen!
How the Stitch Fix Data Platform team actively onboards new users, why it’s necessary for the disruptive technology we’re building, and how to follow suit.
Join the Stitch Fix Algorithms team for Algo-Hour; Feb 16th, 2021 at 2:00PM PST, featuring Dr. Lihua Lei!
In most businesses, the Client Experience (CX) organization is viewed as a cost center. At Stitch Fix, we are using algorithms to help turn this notion on its head.
Join the Stitch Fix Algorithms team for Algo-Hour; Feb 2nd, 2021 at 2:00PM PST, featuring Melanie Weber!
Join the Stitch Fix Algorithms team for Algo-Hour; Jan 26th, 2021 at 2:00PM PST, featuring Art Owen!
Algo Hour, Dec 15th, 2020 - Featuring Michelle Carney!
Algo Hour, Dec 8th, 2020 - Featuring Fei Long!
Bayesian Holiday Modeling for Time Series Inference
Join the Stitch Fix Algorithms team for Algo-Hour; Dec 15th, 2020 at 2:00PM PST, featuring Michelle Carney!
Join the Stitch Fix Algorithms team for Algo-Hour; Dec 8th, 2020 at 2:00PM PST, featuring Fei Long!
When it comes to experimentation, different business models face unique challenges that require thinking beyond the simple randomized control trial to inform decisions critical to the success of companies. At Stitch Fix, we are no exception. Inventory constraints create an undesirable link between observations under different experimental variations. To deal with this, we use the virtual warehouse to split the inventory virtually across variants of an experiment. Furthermore, virtual warehouses also make it easy for us to test different inventory management strategies empirically.
See who's out in the wild for the month of November.
A sampling of the projects and areas of research done by our 2020 summer interns.
More info about the algorithms we use to detect our items' colors
What makes a good estimator? What is an estimator? Why should I care?
A brief introduction to double robust estimation
Algo Hour, Sept 22th, 2020 - Featuring Sean Law!
Join the Stitch Fix Algorithms team for Algo-Hour; Sept 22th, 2020 at 2:00PM PST, featuring Sean Law!
We need to know what colors our merch is. But because downstream users include many different people and algorithms, we need to describe colors as a hierarchy, not just one label.
Algo-Hour; July 28th, 2020 at 2:00PM PST, featuring Clément Delangue!
We've recently built support for multi-armed bandits into the Stitch Fix experimentation platform. This post will explain how and why.
Join the Stitch Fix Algorithms team for Algo-Hour; July 28th, 2020 at 2:00PM PST, featuring Clément Delangue!
Incorporating opportunity costs when running experiments
Algo-Hour; May 19th, 2020 at 2:00PM PST, featuring Leland McInnes!
How and why we built a custom app for visual debugging of warehouse pick paths.
Join the Stitch Fix Algorithms team for Algo-Hour; May 19th, 2020 at 2:00PM PST, featuring Leland McInnes!
The Hive Meta-metastore is part of our recovery mechanism, and once we built it we realized it had other benefits as well. ... Even if you don't have a Hive Metastore, we hope you consider the benefit of building self-service recovery tools in general.
Today we are launching a new interactive visualization. This piece describes the organizational structure, roles, and processes that allows algorithmic capabilities like those depicted in the tour (and many others) to organically emerge.
See who's out in the wild for the month of March.
See who's out in the wild for the month of February.
See who's out in the wild for the month of January.
In some organizations, earnest efforts to be “data-driven” devolve into a culture of false certainty in which the influence of metrics is dictated not by their reliability but rather by their abundance and the confidence with which they’re wielded.
An introduction to the Newsvendor model and exploration of challenges when objectives are cross functional.
A sampling of the projects and areas of research done by our 2019 summer interns.
The diversity of the problems we work on, and the data-rich environment of our business, make it more than possible, even essential, to bring the tools of multiple disciplines to bear on our hardest problems.
Stochastic programming enables optimal decision making in the face of uncertainty.
Running an A/B test is easy. Screwing up an A/B test is even easier.
Embracing AI in our workflows affords better processing of structured data and allows humans to contribute in ways that are complementary.
“Give me jeans not shoes.” That may seem like a simple request, but when we process that bit of text with our human brains, we take a lot for granted.
How many sets of 5 can you make from 10,000 distinct items? Recall that chapter about permutations and combinations...
This post gives practical advice that will help make your ETL pipelines easier to debug, maintain, and extend.
What if you don't need version B to be better than version A?
Listen to the Masters Of Data podcast that features Brad Klingenberg. Hear what it’s like to work on the algorithms team at Stitch Fix and how combining humans and machines may represent the future of work.
This post discusses the benefits of full-stack data science generalists over narrow functional specialists. The later will help you execute and bring process efficiencies. But, the former will help you learn, innovate, and bring a step-change in value - such is the role of data science.
How to create an environment to empower your data scientists to come up with ideas you’ve never dreamed of.
This post explores the use of multi-arm and contextual bandits as a framework for structuring outreach and client engagement programs.
How Stitch Fix designed and built a scalable, centralized and self-service data integration platform tailored to the needs of their Data Scientists.
If we could assign sounds to items of clothing, what would a Fix sound like?
This post explores the use of matrix factorization not just for recommendations, but for understanding style preference more broadly.
This post is an introduction to constrained optimization aimed at data scientists and developers fluent in Python, but without any background in operations research or applied math. We'll demonstrate how optimization modeling can be applied to real problems at Stitch Fix. At the end of this article, you should be able to start modeling your own business problems.
Experimenter beware: Running tests with low power risks much more than missing the detection of true effects.
As data scientists tasked with segmenting clients and products, we find ourselves in the same boat with species taxonomists, straddling the line between lumping individuals into broad groups and splitting into small segments. The approach for drawing the boundaries needs to take into account signals from the data while maintaining sharp focus on the project needs. A balance between lumping and splitting allows us to make the best data-driven decisions we can with the resources we have...
Data scientists are not always equipped with the requisite engineering skills to deploy robust code to a production job execution and scheduling system. Yet, forcing reliance on data platform engineers will impede the scientists autonomy. If only there was another way. So today, we're excited to introduce Flotilla, our latest open source project...
Wow! We are so honored to be ranked #13 on Fast Company’s Most Innovative Companies List. And, we’re thrilled to be ranked #1 on Fast Company’s Data Science List.
It's really gratifying to see Data Science becoming a primary means of strategic differentiation ...
On the Stitch Fix Algorithms team, we’ve always been in awe of what professional stylists are able to do, especially when it comes to knowing a customer’s size on sight. It’s a magical experience to walk into a suit shop, have the professional shopping assistant look you over and without taking a measurement say, “you’re probably a 38, let’s try this one,” and pull out a perfect-fitting jacket. While this sort of experience has been impossible with traditional eCommerce, at Stitch Fix we’re making it a reality.
Counting and tensor decompositions are elegant and straightforward techniques. But these methods are grossly underepresented in business contexts. In this post we factorized an example made up of word skipgrams occurring within documents to arrive at word and document vectors simultaneously. This kind of analysis is effective, simple, and yields powerful concepts.
When I started playing with word2vec four years ago I needed (and luckily had) tons of supercomputer time. But because of advances in our understanding of word2vec, computing word vectors now takes fifteen minutes on a single run-of-the-mill computer with standard numerical libraries1. Word vectors are awesome but you don't need a neural network -- and definitely don't need deep learning -- to find them. So if you're using word vectors and aren't gunning for state of the art or a paper publication then stop using word2vec.
Today is the start of the 2017-2018 NBA Season. Basketball statistics have become a rich and intriguing domain of study, bringing new insights and advantages to the teams that embrace such empiricism. Of course, the framing and analytic techniques used to study basketball are generalizations - they also give intuition to problems in business or other domains (and vice versa). So, for all the basketball statistics enthusiasts out there, as well as those that are looking for inspirations for their own analytic challenges, we thought we’d share a compendium of our past basketball-related posts.
In this post we’ll take a look at how we can model classification prediction with non-constant, time-varying coefficients. There are many ways to deal with time dependence, including Bayesian dynamic models (aka "state space" models), and random effects models. Each type of model captures the time dependence from a different angle; we will keep things simple and look at a time-varying logistic regression that is defined within a regularization framework. We found it quite intuitive, easy to implement, and observed good performances using this model.
Here at Stitch Fix, we work on many fun and interesting areas of Data Science. One of the more unusual ones is drawing maps, specifically internal layouts of warehouses. These maps are extremely useful for simulating and optimising operational processes. In this post, we'll explore how we are combining ideas from recommender systems and structural biology to automatically draw layouts and track when they change.
This summer our community included four interns, all graduate students who are passionate about applying their academic expertise to help us leverage our rich data to better understand our clients, their preferences, and new trends in the industry. In this blog post you’ll meet the interns, who will tell you a bit about the problems they worked on and the strategies they used to solve them.
Stitch Fix is a Data Science company that aspires to help you to find the style that you love. Data Science helps us make most of our business and strategic decisions.
Announcing Diamond, an open-source project for solving mixed-effects models
Solving mixed-effects models efficiently: the math behind Diamond
Analysis should be reproducible. This isn’t controversial, and yet irreproducible analysis is everywhere. I’ve certainly created plenty of it. Why does this happen, despite good intentions? Because, in the short term, it is easier and more expedient not to worry about reproducibility. But this isn’t a moral failing so much as a failing of our tools. Tools can, and should, help make reproducible analysis the natural thing to do. As a step towards encouraging reproducibility, this post introduces Nodebook, an extension to Jupyter notebook.
As a proudly data-driven company dealing with physical goods, Stitch Fix has put lots of effort into inventory management. Tracer, the inventory history service, is a new project we have been building to enable more fine-grained analytics by providing precise inventory state at any given point of time...
In this post aimed at SQL practitioners who would rather spend their time writing Python, we'll show how a web development tool can help your ETL stay DRY.
How to organize an office so everyone working there can be comfortable and productive is the topic of much discussion. A common strategy is to seat people by their team or sub-team membership. Another strategy which we have been employing is to simply allocate people randomly. Building upon these experiences we've developed a new seating allocation tool "seetd", that allows us to frame this as an optimization problem. We're now free to combine these and other approaches objectively.
R is an awesome tool for doing data science interactively, but has some defaults that make us worry about using it in production pipelines.
We have an innate and uncontrollable urge to explain things - even when there is nothing to explain. This post explores why we are prone to narrative fallacies. We start at an epic moment in sports history, Steph Curry breaking the record for most 3-pointers in a game, and draw conclusions for better decision making in business.
Dora helps data scientists at Stitch Fix visually explore their data. Powered by React and Elasticsearch, it provides an intuitive UI for data scientists to take advantage of Elasticsearch's powerful functionality.
In this last installment of our Making of the Tour series, we look at some of the fun and random.
In this post, we'll talk about some simulation-powered animations, provide some cleaned up code that you can use, and discuss these animations' genesis and utility for visualizing abstract systems and algorithms or for visualizing real historical data and projected futures.
Earlier this month, we released an interactive animation describing how data science is woven into the fabric of Stitch Fix: our Algorithms Tour. It was a lot of fun to make and even more fun to see people’s responses to it. For those interested in how we did it, we thought we’d give a quick tour of what lies under that Tour.
Last summer, we wrote about Stitch Fix’s early experiments in data-driven fashion design. Since then, we’ve been studying, developing, and testing new ways to create clothes that delight our clients. Some of this work was featured yesterday in an article in The Wall Street Journal. As a companion to that piece, we wanted to highlight a few avenues that we have explored recently.
How data science is woven into the fabric of Stitch Fix. In this interactive tour we share ten “stories” of how data science is is integral to our operations and product.
At first sight the difference between planets outside our solar system (exoplanets from now on) and fashion trends seems enormous, but all of us math lovers know that entirely different phenomena can have an almost identical mathematical description. In this very peculiar case, exoplanetary systems and certain fashion trends can be characterized as having a periodic nature, with certain magnitudes repeating cyclically, and this will allow us to use very similar techniques to study them.
Time series modeling sits at the core of critical business operations such as supply and demand forecasting and quick-response algorithms like fraud and anomaly detection. Small errors can be costly, so it’s important to know what to expect of different error sources. In this post I’ll go through alternative strategies for understanding the sources and magnitude of error in time series.
For those who attended my talk at Data Day Texas in Austin last weekend, you heard me talk about how Stitch Fix has reduced contention on: Access to data & Access to ad-hoc compute resources; to help scale Data Science. As attendees requested, I have posted my slides here, which you can find a link to...
The outcome of the presidential election clearly indicated that the model used by FiveThirtyEight was closer to the truth than that of the Princeton Election Consortium in terms of the level of uncertainty in the predictions---but not by as much as you might think. I consider the question quantitatively: what are the odds that one or the other model is right given the state-by-state results?
When Donald Trump won the 2016 presidential election, both sides of the political spectrum were surprised. The prediction models didn't see it coming and the Nate Silvers of the world took some heat for that (although Nate Silver himself got pretty close). After this, a lot of people would probably agree that the world doesn't need another statistical prediction model.
So, should we turn our backs on forecasting models? No, we just need to revise our expectations. George Box once reminded us that statistical models are, at best, useful *approximations* of the real world. With the recent hype around data science and "money balling" this point is often overlooked.
On this day in 1936, Alan Turing stood before the London Mathematical Society and delivered a paper entitled "On Computable Numbers, with an Application to the Entscheidungsproblem", wherein he described an abstract mathematical device that he called a "universal computing engine" and which would later become known as a Turing machine. As a Stitch Fix tribute, we’ve melded a Turing machine and a 1936 Singer sewing machine.
Update, Dec 12, 2016: There is a follow up post discussing the outcome of all of this after the election results were known.
Plaid is for fall; red on Valentine’s Day; no white after Labor Day. These are fashion adages we’ve all heard before -- that even John Oliver promotes. But how true are they? The Stitch Fix Algorithms team is in a unique position to quantitatively answer these questions for the first time. Given the season, we’ve decided to first take a look at the “No white after Labor Day” claim. How real is it?
Data science begins not with data but with questions. And sometimes getting the data necessary to answer those questions requires some ingenuity.
On the algorithms team at Stitch Fix, we aim to give everyone enough autonomy to own and deploy all the code that they write, when and how they want to. This is challenging because the breadth of who is writing micro-services for what, covers a wide spectrum of use cases - from writing services to integrate with engineering applications, e.g. serving styling recommendations, to writing dashboards that consume and display data, to writing internal services to help make all of this function. After looking at the many deployment pipeline options out there, we settled on implementing the immutable server pattern.
Data is embraced as a first class citizen at Stitch Fix. In order to power our complex machine learning algorithms used for styling, inventory management, fix scheduling and many other smart services, it is critical to have a scalable data pipeline implementation. This pipeline must consume and move data efficiently as well as provide low latency, high availability, and visibility.
At Stitch Fix, we build tools that help us to delight our clients, which includes performing the thoughtful research that enables such tools. A great example of this is how we study methods for identifying temporal trends. Consider seasonality, which describes the cyclical patterns in how our client’s preferences change over a year. Identifying seasonal trends requires a mixture of time series analysis and machine learning that is challenging but of critical importance to a fashion retail organization.
It's natural to want to sit next to the people we work with most. Doing so makes pair-coding easier, facilitates conversations that need to happen anyway, and — in general — promotes a certain efficiency.
There's an alternative point of view, though: if people who don't often work closely together sit together, conversations will occur that otherwise would not.
Members of our Analytics & Algorithms team are out and about this month – come by and hear us speak!
Here at Stitch Fix we work on a wide and varied set of data science problems. One area that we are heavily involved with is operations. Operations covers a broad range of problems and can involve things like optimizing shipping, allocating items to warehouses, coordinating processes to ensure that our products arrive on time, or optimizing the internal workings of a warehouse.
A core methodology at Stitch Fix is blending recommendations from machines with judgments of expert humans. Our machines produce recommendations via algorithms operating over structured data, while our human stylists curate and modify these recommendations on the basis of unstructured data and knowledge that isn’t yet reflected in our dataset (e.g., new fashion trends). This helps us choose the best 5 items to offer each client in each fix. The success of this strategy within our styling organization prompts consideration of how machines and humans might be brought together in the realm of fashion design. In this post we describe one implementation of such a system. In particular, we explore how the system could be implemented with respect to a target client segment and season.
Members of our Analytics & Algorithms team are out and about this month – come by and hear us speak!
Machines are going to take over the world and leave us humans without jobs. This is the meme going around in mainstream business books on the topic of Artificial Intelligence (AI). This is understandable as the number of things that machines can do better than humans is increasing: diagnosing medical conditions, analyzing legal documents, making parole decisions, to name a few. But doing something better doesn’t necessarily make machines an alternative to humans. If machines and humans each contribute differently to a capability, then there is opportunity to combine their unique talents to produce an outcome that is better than either one could achieve on their own. This has real potential to change not only how we work, but also how we understand our experience of being human.
One of the greatest benefits of working among a diverse group of data scientists and data engineers at Stitch Fix is how much we can learn from our peers. Usually that means getting ad hoc help with specific questions from the resident expert(s). But it also means getting advice on how best to fill any gaps in our own skill sets or knowledge bases, or just what interesting data science materials to explore in our spare time. Our blog posts usually highlight the former; this post touches on the latter.
The goal of lda2vec is to make volumes of text useful to humans (not machines!) while still keeping the model simple to modify. It learns the powerful word representations in word2vec while jointly constructing human-interpretable LDA document representations.
Beautiful data visualizations reveal stories that mere numbers cannot tell. Using visualizations, we can get a sense of scale, speed, direction, and trend of the data. Additionally, we can draw the attention of the audience – the key to any successful presentation – in a way that’s impossible with dry tabulations. While a tabular view of new online signups is informative for tracking, a dynamic map would provide a more captivating view and reveal dimensions that a table cannot.
When people think of “data science” they probably think of algorithms that scan large datasets to predict a customer’s next move or interpret unstructured text. But what about models that utilize small, time-stamped datasets to forecast dry metrics such as demand and sales? Yes, I’m talking about good old time series analysis, an ancient discipline that hasn’t received the cool “data science” rebranding enjoyed by many other areas of analytics.
As data scientists, we work in concert with other members of an organization with the goal of making better decisions. This often involves finding trends and anomalies in historical data to guide future action. But in some cases, the best aid to decision-making is less about finding “the answer” in the data and more about developing a deeper understanding of the underlying problem. In this post we will focus another tool that is often overlooked: interactive simulations through the means of agent based modeling.
Stitch Fix values the input of both human experts and computer algorithms in our styling process. As we’ve pointed out before, this approach has a lot of benefits and so it’s no surprise that more and more technologies (like Tesla’s self-driving cars, Facebook’s chat bot, and Wise.io’s augmented customer service) are also marrying computer and human workforces. Interest has been rising in how to optimize this type of hybrid algorithm. At Stitch Fix we have realized that well-trained humans are just as important for this as well-trained machines.
As statisticians and data scientists, we often set out to test the null hypothesis. We acquire some data, apply some statistical tests, and see what the p-value is. If we find a sufficiently-low p-value, we reject the null hypothesis, which is commonly referred to as \(H_0\).
Over the last couple of years, Stitch Fix has amassed one of the more impressive data science teams around. The team has grown to 65 people, collaborates with all areas of the business, and has a well-respected data science blog plus several open source contributions.
As a member of this team since late 2014, and someone who has spent 15 years in the analytics space prior to that, I’ve often reflected on how the data science team at Stitch Fix got to this point. Is it attributable to our business model? Or, is Stitch Fix doing something differently when it comes to growing and managing its data science team?
The short answer is that the business model does provide a fertile environment for data science. However, it goes deeper than that: the approach to managing and building data science teams at Stitch Fix is unique in many ways. In fact, it has debunked many of the beliefs I held about management and growth prior to joining the team.
We now rely on algorithms to tell us what movies to watch, what cat food to buy, and we’re even starting to let them drive our cars. That said, there’s still something a little odd about an algorithm picking out a dress for your date on Saturday night or the perfect tie for your best friend’s wedding. The simple fact is that computers can do a lot these days, but while their capabilities continue to develop there are still many things that humans do better.
When we experience volatility in business metrics we tend to grasp for explanations. We fall for availability bias, and the more visceral or intuitive the explanation the quicker we latch on. ‘The cool weather is dissuading customers’, ‘customers are happier on Fridays because the weekend is coming’, ‘people are concerned with the economic downturn’, ‘competitor xyz is making a lot of noise in the market which is diluting our messaging’, … etc. The list goes on and on.
“What is the relationship like between your team and the data scientists?” This is, without a doubt, the question I’m most frequently asked when conducting interviews for data platform engineers. It’s a fine question – one that, given the state of engineering jobs in the data space, is essential to ask as part of doing due diligence in evaluating new opportunities. I’m always happy to answer. But I wish I didn’t have to, because this a question that is motivated by skepticism and fear.
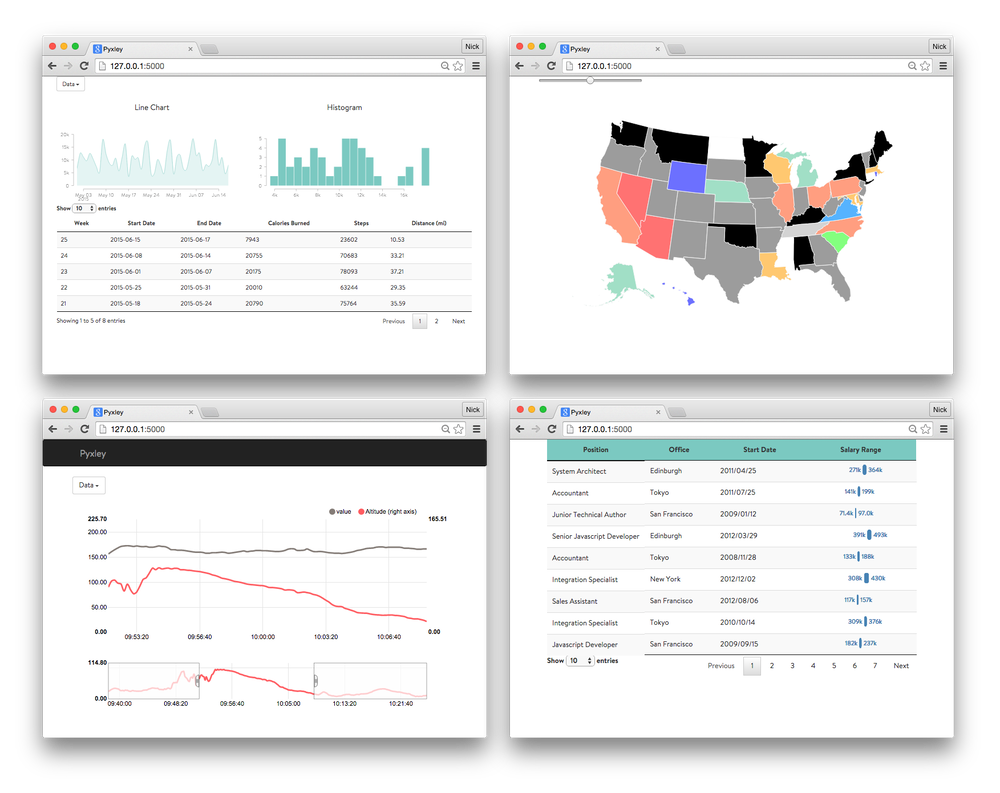
The Algorithms team is deeply embedded in every aspect of Stitch Fix, providing insights and recommendations to help our business partners make data-driven decisions. Pyxley was born out of the need to deliver those insights without spending a lot of time on front-end design. The original plan with Pyxley was to start off with a small set of simple components and then add new components into the package as they were developed for various dashboards. Unfortunately there was one fatal flaw in that plan: our team loves Tables. Sortable tables, tables with two headers, and even tables within tables. Therefore, despite having built several dashboards, there hasn’t been a need to increase the set of components.
“What’s your size?”
Back in September – before the start of the 2015-2016 NBA season – we wrote a post about the Golden State Warriors that was titled “Strength in Numbers: Why Golden State Deserved to Win in All.” The post explored whether Golden State got lucky last season. Were they carried by their momentum and aided by injuries to the opposing teams, or did they simply have the best basketball DNA? Our conclusion was that Golden State did indeed have the best DNA, although the final series against Cleveland would have been a very close series if Kevin Love and Kyrie Irving had been healthy.
When it comes to data, Stitch Fix and its customers have a symbiotic relationship. The more information we have about a customer’s preference in clothing, the better we can cater to them with clothes that match their liking. Our customers are aware of this and in turn provide high quality feedback on pricing, color, style, attributes to avoid, and so much more.
The field of computer vision is rapidly evolving, particularly in the area of unsupervised deep learning. Over the past year or so there have been many new and exciting methods developed to both represent and generate images in an automated fashion, but the field is evolving so rapidly that it can be hard to keep track of all these methods. I recently gave a research talk to the Styling Algorithms team here at Stitch Fix on the current state of the art (as I see it) in unsupervised computer vision research. It was by no means comprehensive, but more of a survey of of interesting methods I thought might be applicable to a problem I have been working on recently: how does one disentangle attributes at the level of a latent image representation?
Two weeks ago there was a lot of buzz around Erik Bernhardsson’s blog post, where he trained an autoencoder on more than 50,000 fonts. The results are fantastic and if you haven’t seen it yet, go check it out. A few months back we released a package called fauxtograph, which performs unsupervised deep learning on images via variational autoencoding (VAE). Less than a week ago we implemented some big changes in fauxtograph where convolutional and adversarial network (GAN) capabilities were added. So how will the updates in the package do with the fonts dataset that Erik shared?
If you ever spent time in the field of marketing analytics, chances are that you have analyzed the existence of a causal impact from a new local TV campaign, a major PR event, or the emergence of a new local competitor. From an analytical standpoint these types of events all have one thing in common: The impact cannot be tracked at the individual customer level and hence we have to analyze the impact from a bird's eye view using time series analysis at the market level. Data science may be changing at a fast pace but this is an old-school use-case that is still very relevant no matter what industry you're in.
Jupyter and D3 have both become staples in the data science toolkit: Jupyter for interactive data analysis and D3 for interactive data visualization. There has recently been a growing array of options for using the two together - such as mpld3, bokeh, plotly and others - but these tools usually focus on the use case of a Python or R programmer who would rather not dig too far into JavaScript, and thus somewhat limit the otherwise immense flexibility available with D3. For those who want the full breadth of possibilities, there is another approach shown below. Be sure to play with the force graph!
Neural networks provide a vast array of functionality in the realm of statistical modeling, from data transformation to classification and regression. Unfortunately, due to the computational complexity and generally large magnitude of data involved, the training of so called deep learning models has been historically relegated to only those with considerable computing resources. However with the advancement of GPU computing, and now a large number of easy-to-use frameworks, training such networks is fully accessible to anybody with a simple knowledge of Python and a personal computer. In this post we’ll go through the process of training your first neural network in Python using an exceptionally readable framework called Chainer. You can follow along this post through the tutorial here or via the Jupyter Notebook.
When we our betters see bearing our WOEs,
We scarcely think our miseries our foes.
From King Lear
The Golden State Warriors won the NBA finals last year and posted the best record in the regular season. Yet some people have argued that their success was based on luck and that playing “small ball” is a recipe that only works in the regular season.
In recent years, there has been a lot of attention on hypothesis testing and so-called “p-hacking”, or misusing statistical methods to obtain more “significant” results. Rightly so: For example, we spend millions of dollars on medical research, and we don’t want to waste our time and money, pursuing false leads caused by flaky statistics. But even if all of our assumptions are met and our data collection is flawless, it’s not always easy to get the statistics right; there are still quite a few subtleties that we need to be aware of.
Data science is a new field, and it isn’t always obvious what makes a good data scientist. What should they know? Tools, frameworks, and technologies are always changing. In the midst of this shifting landscape data scientists can differentiate themselves by mastering one of the most useful tools from applied statistics: linear modeling. Last week I spoke to the latest class of fellows at Insight about this very topic and the slides from my talk can be found here.
Spark is a cluster computing framework that can significantly increase the efficiency and capabilities of a data scientist’s workflow when dealing with distributed data. However, deciding which of its many modules, features and options are appropriate for a given problem can be cumbersome. Our experience at Stitch Fix has shown that these decisions can have a large impact on development time and performance. This post will discuss strategies at each stage of the data processing workflow which data scientists new to Spark should consider employing for high productivity development on big data.
When I made the change from my postdoc role in neuroscience to data science at Stitch Fix, I was hoping to get to do more of the thing I loved most about being a scientist: collaborative data-driven discovery. That’s exactly what I got, and I have the data to prove it.
 Here at Stitch Fix, we are always looking for new ways to improve our client experience. On the algorithms side that means helping our stylists to make better fixes through a robust recommendation system. With that in mind, one path to better recommendations involves creating an automated process to understand and quantify the style our inventory and clients at a fundamental level. Few would doubt that fashion is primarily a visual art form, so in order to achieve this goal we must first develop a way to interpret the style within images of clothing. In this post we’ll look specifically at how to build an automated process using photographs of clothing to quantify the style of some of items in our collection. Then we will use this style model to make new computer generated clothing like the image to the right.
Here at Stitch Fix, we are always looking for new ways to improve our client experience. On the algorithms side that means helping our stylists to make better fixes through a robust recommendation system. With that in mind, one path to better recommendations involves creating an automated process to understand and quantify the style our inventory and clients at a fundamental level. Few would doubt that fashion is primarily a visual art form, so in order to achieve this goal we must first develop a way to interpret the style within images of clothing. In this post we’ll look specifically at how to build an automated process using photographs of clothing to quantify the style of some of items in our collection. Then we will use this style model to make new computer generated clothing like the image to the right.
In March of 2016, SXSW will be hosting the Interactive Festival in Austin, Texas. The festival is focussed on the mindshare of cutting-edge technologies and digital creativity where people get a glimmer of what the future has to offer. Eric Colson and Eli Bressert are both planning to be there and talk about changing industries with data analytics and how machines take on art. The talks are being considered by the judges until September 4th where public voting will account for 30% of their considearation.
Binary classification models are perhaps the most common use-case in predictive analytics. The reason is that many key client actions across a wide range of industries are binary in nature, such as defaulting on a loan, clicking on an ad, or terminating a subscription.
Imagine that you step into a room of data scientists; the dress code is casual and the scent of strong coffee is hanging in the air. You ask the data scientists if they regularly use generalized additive models (GAM) to do their work. Very few will say yes, if any at all.
At Stitch Fix we have many problems that boil down to finding the best match between items in two sets. Our recommendation algorithms match inventory to clients with the help of the expert human judgment of our stylists. We also match these stylists to clients. This blog post is about the remarkably useful application of some classical statistical models to these and similar problems that feature repeated measurements.
There is an old story of a commander who, upon landing on the beach of his adversary, ordered “burn the boats” so that his warriors would have no other choice but to triumph. The imposed constraint provided clarity. The lack of a fallback mechanism and the high cost of failure focused all efforts towards victory.
Throughout the year, people wear different types of clothes. As we transition from Summer to Fall, tanktops are replaced by sweaters, and as Spring turns into Summer, pants are replaced by shorts and skirts. But what about colors? Do people wear different colors to match the seasons? From anecdotal experience we would say yes. One might even guess that people tend to wear more gray/black clothing in New York vs. sunny Los Angeles during the Winter.
Although a commonly used phrase, there is no such thing as a “statistically significant sample” – it’s the result that can be statistically significant, not the sample. Word-mincing aside, for any study that requires sampling – e.g. surveys and A/B tests – making sure we have enough data to ensure confidence in results is absolutely critical.
At Stitch Fix we are avid users of Jupyter for research at both the personal and team scales. At the personal level, Jupyter is a great interface to research the question at hand. It captures the workflow of the research where we can take detailed notes on the code and explain models with written content and mathematical equations.
It’s a good time to be a data scientist. If you have the skills, experience, curiosity and passion, there is a vast and receptive market of companies to choose from. Yet there is much to consider when evaluating a prospective firm as a place to apply your talents. Even veterans may not have had the opportunity to experience different organizations, stages of maturity, cultures, technologies, or domains. We are amalgamating our combined experience here to offer some advice - three things to look for in a company that could make it a great place to work.
Python and R are popular programming languages used by data scientists. Until recently, I exclusively used Python for exploratory data analysis, relying on Pandas and Seaborn for data manipulation and visualization. However, after seeing my colleagues do some amazing work in R with dplyr and ggplot2, I decided to take the plunge and learn how the other side lives. I found that I could more easily translate my ideas into code and beautiful visualizations with R than with Python. In this post, I will elaborate on my experience switching teams by comparing and contrasting R and Python solutions to some simple data exploration exercises.
Standard natural language processing (NLP) is a messy and difficult affair. It requires teaching a computer about English-specific word ambiguities as well as the hierarchical, sparse nature of words in sentences. At Stitch Fix, word vectors help computers learn from the raw text in customer notes. Our systems, composed of machines and human experts, need to recommend the maternity line when she says she’s in her ‘third trimester’, identify a medical professional when she writes that she ‘used to wear scrubs to work’, and distill ‘taking a trip’ into a Fix for vacation clothing.
Last week we kicked off our first Multithreaded Data event, where John Myles White gave a talk about Julia, a new programming language that some of us love. It’s the first of many exciting talks to come at Stitch Fix. Our next invited speaker is Hadley Wickham, who will be talking about how to get data into R. If you’re in the SF bay area and the topic excites you, keep an eye out for our upcoming events!
The frequentist paradigm enjoys the most widespread acceptance for statistical analysis. Frequentist concepts such as confidence intervals and p-values dominate introductory statistics curriculums from science departments to business schools, and frequentist methods are still the go-to tools for most practitioners.
In data science, or any related quantitative field, we strive to understand and leverage our data for our objectives. These data will usually be part of a bigger project that we’re working on where the workflow looks something like the following:
For the past half year I’ve been exploring Julia in piecemeal fashion. It’s a language that does not conform to the traditional notions of programming. Julia is a high-level, dynamic language (like Python) and is on par with C and Fortran in performance.
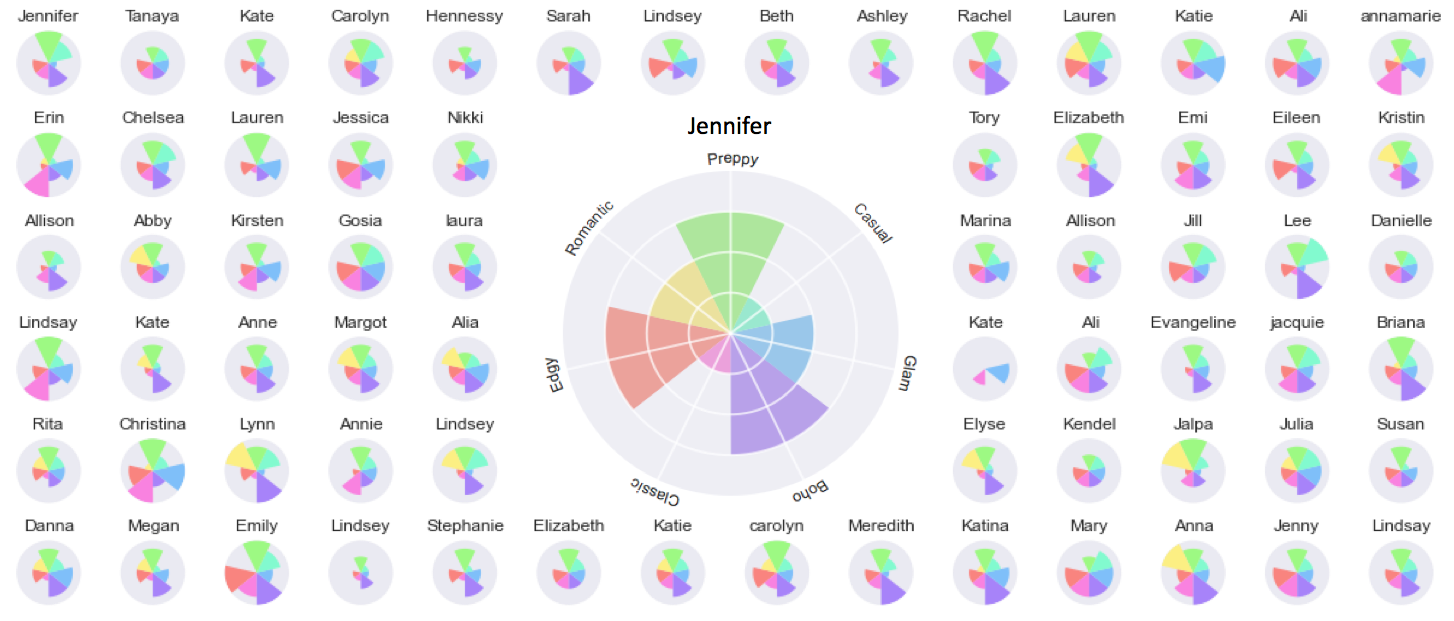
The process of selecting just the right merchandise for each of our clients is not a simple one; there is much that needs to be taken into account. There are parts of the process that can be broken down and framed as a mathematical model of client utility. Here, the individual preferences for each client can be modeled and validated empirically through machine processing of structured data. However, there are other parts that evade such strict rationality assumptions and tend to be better evaluated emotionally or from information not manifested in structured data. For this, we need to rely on the judgments of expert-humans. Each piece contributes distinct value to the overall selection process and exclusive focus on either one would be incomplete. For this reason, the Stitch Fix styling application has been architected to leverage diverse resources - both machines and expert-humans - in order to exhaust all available information and processing.
I just returned having spent a great day in Los Angeles, CA (at UCLA main campus) where I had the pleasure of giving a talk at the R User 2014 Conference. The conference brought together top users and developers of R. It was a great place to share ideas on how to best apply the R language and its tools to address challenges in data management, processing, analytics and visualization.
I am excited to announce the newest addition to the Stitch Fix algorithms team, Jeff Magnusson. Jeff will join us as the Director of Data Platform, and will be primarily responsible for developing the architecture on which the Stitch Fix algorithms will run.